I previously annotated our Olurida_v081 genome with MAKER using our “canonical” transcriptome, Olurida_transcriptome_v3.fasta as the EST evidence utilized by MAKER. A discussion on one of our Slack channels related to the lack of isoform annotation (I think it’s a private channel, sorry) prompted Katherine Silliman to suggest re-running the annotation using tissue-specific transcriptome assemblies that she has generated as EST evidence, instead of a singular transcriptome. Since I already had previous versions of the MAKER script that I’ve used for annotations, re-running was rather straightforward. While this was running, I used Stringtie on 20190625to produce a GTF that maps out potential isoforms, as I don’t believe MAKER will actually predict isoforms, since it didn’t do so the first time, nor has it with other annotations we’ve run on geoduck assemblies.
Running MAKER will perform the following:
- one round of MAKER gene model predictions
- two rounds of SNAP gene model training/predictions
- renaming of gene models to NCBI-standardized convention (e.g. OLUR_)
- functional characterization of protein models (via BLASTp)
- functional characterization of protein domains (via InterProScan5)
Here are a list of the input files used for the various components of the MAKER annotation:
Transcriptome FastA files (provided by Katherine Silliman; no creation info provided):
NCBI Protein FastA files
NCBI Crassostrea gigas proteome (downloaded 20181119):
GCA_000297895.1_oyster_v9_protein.faaNCBI Crassostrea virginica proteome (downloaded 20181119):
GCF_002022765.2_C_virginica-3.0_protein.faaSwissProt BLASTp database(downloaded 20190109): uniprot_sprot.fasta
Repeats Files (links to notebook entries)
SBATCH script (GitHub):
#!/bin/bash
## Job Name
#SBATCH --job-name=maker_olur-v081
## Allocation Definition
#SBATCH --account=coenv
#SBATCH --partition=coenv
## Resources
## Nodes
#SBATCH --nodes=2
## Walltime (days-hours:minutes:seconds format)
#SBATCH --time=40-00:00:00
## Memory per node
#SBATCH --mem=120G
##turn on e-mail notification
#SBATCH --mail-type=ALL
#SBATCH --mail-user=samwhite@uw.edu
## Specify the working directory for this job
#SBATCH --workdir=/gscratch/scrubbed/samwhite/outputs/20190709_maker_olur_v081_annotation
# Exit if any command fails
set -e
# Load Python Mox module for Python module availability
module load intel-python3_2017
# Load Open MPI module for parallel, multi-node processing
module load icc_19-ompi_3.1.2
# SegFault fix?
export THREADS_DAEMON_MODEL=1
# Add BLAST to system PATH
export PATH=$PATH:/gscratch/srlab/programs/ncbi-blast-2.6.0+/bin
export BLASTDB=/gscratch/srlab/blastdbs/UniProtKB_20181008
# Document programs in PATH (primarily for program version ID)
date >> system_path.log
echo "" >> system_path.log
echo "System PATH for $SLURM_JOB_ID" >> system_path.log
echo "" >> system_path.log
printf "%0.s-" {1..10} >> system_path.log
echo "${PATH}" | tr : \\n >> system_path.log
## Establish variables for more readable code
wd=$(pwd)
maker_dir=/gscratch/srlab/programs/maker-2.31.10/bin
snap_dir=/gscratch/srlab/programs/maker-2.31.10/exe/snap
### Paths to Maker binaries
maker=${maker_dir}/maker
gff3_merge=${maker_dir}/gff3_merge
maker2zff=${maker_dir}/maker2zff
fathom=${snap_dir}/fathom
forge=${snap_dir}/forge
hmmassembler=${snap_dir}/hmm-assembler.pl
fasta_merge=${maker_dir}/fasta_merge
map_ids=${maker_dir}/maker_map_ids
map_gff_ids=${maker_dir}/map_gff_ids
map_fasta_ids=${maker_dir}/map_fasta_ids
functional_fasta=${maker_dir}/maker_functional_fasta
functional_gff=${maker_dir}/maker_functional_gff
ipr_update_gff=${maker_dir}/ipr_update_gff
iprscan2gff3=${maker_dir}/iprscan2gff3
blastp_dir=${wd}/blastp_annotation
maker_blastp=${wd}/blastp_annotation/blastp.outfmt6
maker_prot_fasta=${wd}/snap02/Olurida_v081_snap02.all.maker.proteins.fasta
maker_prot_fasta_renamed=${wd}/snap02/Olurida_v081_snap02.all.maker.proteins.renamed.fasta
maker_transcripts_fasta=${wd}/snap02/Olurida_v081_snap02.all.maker.transcripts.fasta
maker_transcripts_fasta_renamed=${wd}/snap02/Olurida_v081_snap02.all.maker.transcripts.renamed.fasta
snap02_gff=${wd}/snap02/Olurida_v081_snap02.all.gff
snap02_gff_renamed=${wd}/snap02/Olurida_v081_snap02.all.renamed.gff
put_func_gff=Olurida_v081_genome_snap02.all.renamed.putative_function.gff
put_func_prot=Olurida_v081_genome_snap02.all.maker.proteins.renamed.putative_function.fasta
put_func_trans=Olurida_v081_genome_snap02.all.maker.transcripts.renamed.putative_function.fasta
put_domain_gff=Olurida_v081_genome_snap02.all.renamed.putative_function.domain_added.gff
ips_dir=${wd}/interproscan_annotation
ips_base=Olurida_v081_maker_proteins_ips
ips_name=Olurida_v081_maker_proteins_ips.tsv
id_map=${wd}/snap02/Olurida_v081_genome.map
ips_domains=Olurida_v081_genome_snap02.all.renamed.visible_ips_domains.gff
## Path to blastp
blastp=/gscratch/srlab/programs/ncbi-blast-2.6.0+/bin/blastp
## Path to InterProScan5
interproscan=/gscratch/srlab/programs/interproscan-5.31-70.0/interproscan.sh
## Store path to options control file
maker_opts_file=./maker_opts.ctl
### Path to genome FastA file
genome=/gscratch/srlab/sam/data/O_lurida/genomes/Olurida_v081/Olurida_v081.fa
### Paths to transcriptome FastA files
adductor_transcriptome=/gscratch/srlab/sam/data/O_lurida/transcriptomes/Olurida_CA_adductor_Trinity.fasta
ctendia_transcriptome=/gscratch/srlab/sam/data/O_lurida/transcriptomes/Olurida_CA_ctenidia_Trinity.fasta
gonad_transcriptome=/gscratch/srlab/sam/data/O_lurida/transcriptomes/Olurida_gonad_Trinity.fasta
mantle_transcriptome=/gscratch/srlab/sam/data/O_lurida/transcriptomes/Olurida_CA_mantle_Trinity.fasta
### Path to Crassotrea gigas NCBI protein FastA
gigas_proteome=/gscratch/srlab/sam/data/C_gigas/gigas_ncbi_protein/GCA_000297895.1_oyster_v9_protein.faa
### Path to Crassostrea virginica NCBI protein FastA
virginica_proteome=/gscratch/srlab/sam/data/C_virginica/virginica_ncbi_protein/GCF_002022765.2_C_virginica-3.0_protein.faa
### Path to O.lurida-specific RepeatModeler library
repeat_library=/gscratch/srlab/sam/data/O_lurida/repeats/Ostrea_lurida_v081-families.fa
### Path to O.lurida-specific RepeatMasker GFF
rm_gff=/gscratch/srlab/sam/data/O_lurida/repeats/Olurida_v081.fa.out.gff
### Path to SwissProt database for BLASTp
sp_db_blastp=/gscratch/srlab/blastdbs/UniProtKB_20190109/uniprot_sprot.fasta
## Make directories
mkdir blastp_annotation
mkdir interproscan_annotation
mkdir snap01
mkdir snap02
## Create Maker control files needed for running Maker, only if it doesn't already exist and then edit it.
### Edit options file
### Set paths to O.lurida genome and transcriptome.
### Set paths to C. gigas and C.virginica proteomes.
### The use of the % symbol sets the delimiter sed uses for arguments.
### Normally, the delimiter that most examples use is a slash "/".
### But, we need to expand the variables into a full path with slashes, which screws up sed.
### Thus, the use of % symbol instead (it could be any character that is NOT present in the expanded variable; doesn't have to be "%").
if [ ! -e maker_opts.ctl ]; then
$maker -CTL
sed -i "/^genome=/ s% %$genome %" "$maker_opts_file"
# Set transcriptomes to use
sed -i "/^est=/ s% %\
${adductor_transcriptome},\
${ctendia_transcriptome},\
${gonad_transcriptome},\
${mantle_transcriptome} \
%" \
"$maker_opts_file"
# Set proteomes to use
sed -i "/^protein=/ s% %\
${gigas_proteome},\
${virginica_proteome} \
%" \
"$maker_opts_file"
# Set RepeatModeler library to use
sed -i "/^rmlib=/ s% %$repeat_library %" "$maker_opts_file"
# Set RepeatMasker GFF to use
sed -i "/^rm_gff=/ s% %${rm_gff} %" "$maker_opts_file"
# Set est2ggenome to 1 - tells MAKER to use transcriptome FastAs
sed -i "/^est2genome=0/ s/est2genome=0/est2genome=1/" "$maker_opts_file"
# Set protein2genome to 1 - tells MAKER to use protein FastAs
sed -i "/^protein2genome=0/ s/protein2genome=0/protein2genome=1/" "$maker_opts_file"
fi
## Run Maker
### Specify number of nodes to use.
mpiexec -n 56 $maker
## Merge gffs
${gff3_merge} -d Olurida_v081.maker.output/Olurida_v081_master_datastore_index.log
## GFF with no FastA in footer
${gff3_merge} -n -s -d Olurida_v081.maker.output/Olurida_v081_master_datastore_index.log > Olurida_v081.maker.all.noseqs.gff
## Merge all FastAs
${fasta_merge} -d Olurida_v081.maker.output/Olurida_v081_master_datastore_index.log
## Extract GFF alignments for use in subsequent MAKER rounds
### Transcript alignments
awk '{ if ($2 == "est2genome") print $0 }' Olurida_v081.maker.all.noseqs.gff > Olurida_v081.maker.all.noseqs.est2genome.gff
### Protein alignments
awk '{ if ($2 == "protein2genome") print $0 }' Olurida_v081.maker.all.noseqs.gff > Olurida_v081.maker.all.noseqs.protein2genome.gff
### Repeat alignments
awk '{ if ($2 ~ "repeat") print $0 }' Olurida_v081.maker.all.noseqs.gff > Olurida_v081.maker.all.noseqs.repeats.gff
## Run SNAP training, round 1
cd "${wd}"
cd snap01
${maker2zff} ../Olurida_v081.all.gff
${fathom} -categorize 1000 genome.ann genome.dna
${fathom} -export 1000 -plus uni.ann uni.dna
${forge} export.ann export.dna
${hmmassembler} genome . > Olurida_v081_snap01.hmm
## Initiate second Maker run.
### Copy initial maker control files and
### Default gene prediction settings are 0 (i.e. don't generate Maker gene predictions)
### - use GFF subsets generated in first round of MAKER
### - set location of snaphmm file to use for gene prediction
### Percent symbols used below are the sed delimiters, instead of the default "/",
### due to the need to use file paths.
if [ ! -e maker_opts.ctl ]; then
$maker -CTL
sed -i "/^genome=/ s% %$genome %" maker_opts.ctl
# Set transcriptomes to use
sed -i "/^est=/ s% %\
${adductor_transcriptome},\
${ctendia_transcriptome},\
${gonad_transcriptome},\
${mantle_transcriptome} \
%" \
"$maker_opts_file"
# Set proteomes to use
sed -i "/^protein=/ s% %\
${gigas_proteome},\
${virginica_proteome} \
%" \
"$maker_opts_file"
# Set RepeatModeler library to use
sed -i "/^rmlib=/ s% %$repeat_library %" "$maker_opts_file"
sed -i "/^est_gff=/ s% %../Olurida_v081.maker.all.noseqs.est2genome.gff %" maker_opts.ctl
sed -i "/^protein_gff=/ s% %../Olurida_v081.maker.all.noseqs.protein2genome.gff %" maker_opts.ctl
sed -i "/^rm_gff=/ s% %../Olurida_v081.maker.all.noseqs.repeats.gff %" maker_opts.ctl
sed -i "/^snaphmm=/ s% %Olurida_v081_snap01.hmm %" maker_opts.ctl
fi
## Run Maker
### Set basename of files and specify number of CPUs to use
mpiexec -n 56 $maker \
-base Olurida_v081_snap01
## Merge gffs
${gff3_merge} -d Olurida_v081_snap01.maker.output/Olurida_v081_snap01_master_datastore_index.log
## GFF with no FastA in footer
${gff3_merge} -n -s -d Olurida_v081_snap01.maker.output/Olurida_v081_snap01_master_datastore_index.log > Olurida_v081_snap01.maker.all.noseqs.gff
## Run SNAP training, round 2
cd "${wd}"
cd snap02
${maker2zff} ../snap01/Olurida_v081_snap01.all.gff
${fathom} -categorize 1000 genome.ann genome.dna
${fathom} -export 1000 -plus uni.ann uni.dna
${forge} export.ann export.dna
${hmmassembler} genome . > Olurida_v081_snap02.hmm
## Initiate third and final Maker run.
if [ ! -e maker_opts.ctl ]; then
$maker -CTL
sed -i "/^genome=/ s% %$genome %" maker_opts.ctl
# Set transcriptomes to use
sed -i "/^est=/ s% %\
${adductor_transcriptome},\
${ctendia_transcriptome},\
${gonad_transcriptome},\
${mantle_transcriptome} \
%" \
"$maker_opts_file"
# Set proteomes to use
sed -i "/^protein=/ s% %\
${gigas_proteome},\
${virginica_proteome} \
%" \
"$maker_opts_file"
# Set RepeatModeler library to use
sed -i "/^rmlib=/ s% %$repeat_library %" "$maker_opts_file"
sed -i "/^est_gff=/ s% %../Olurida_v081.maker.all.noseqs.est2genome.gff %" maker_opts.ctl
sed -i "/^protein_gff=/ s% %../Olurida_v081.maker.all.noseqs.protein2genome.gff %" maker_opts.ctl
sed -i "/^rm_gff=/ s% %../Olurida_v081.maker.all.noseqs.repeats.gff %" maker_opts.ctl
sed -i "/^snaphmm=/ s% %Olurida_v081_snap02.hmm %" maker_opts.ctl
fi
## Run Maker
### Set basename of files and specify number of CPUs to use
mpiexec -n 56 $maker \
-base Olurida_v081_snap02
## Merge gffs
${gff3_merge} \
-d Olurida_v081_snap02.maker.output/Olurida_v081_snap02_master_datastore_index.log
## GFF with no FastA in footer
${gff3_merge} -n -s -d Olurida_v081_snap02.maker.output/Olurida_v081_snap02_master_datastore_index.log > Olurida_v081_snap02.maker.all.noseqs.gff
## Merge FastAs
${fasta_merge} \
-d Olurida_v081_snap02.maker.output/Olurida_v081_snap02_master_datastore_index.log
# Create copies of files for mapping
cp "${maker_prot_fasta}" "${maker_prot_fasta_renamed}"
cp "${maker_transcripts_fasta}" "${maker_transcripts_fasta_renamed}"
cp "${snap02_gff}" "${snap02_gff_renamed}"
# Map IDs
## Change gene names
${map_ids} \
--prefix OLUR_ \
--justify 8 \
"${snap02_gff}" \
> "${id_map}"
## Map GFF IDs
${map_gff_ids} \
"${id_map}" \
"${snap02_gff_renamed}"
## Map FastAs
### Proteins
${map_fasta_ids} \
"${id_map}" \
"${maker_prot_fasta_renamed}"
### Transcripts
${map_fasta_ids} \
"${id_map}" \
"${maker_transcripts_fasta_renamed}"
# Run InterProScan 5
## disable-precalc since this requires external database access (which Mox does not allow)
cd "${ips_dir}"
${interproscan} \
--input "${maker_prot_fasta_renamed}" \
--goterms \
--output-file-base ${ips_base} \
--disable-precalc
# Run BLASTp
cd "${blastp_dir}"
${blastp} \
-query "${maker_prot_fasta_renamed}" \
-db ${sp_db_blastp} \
-out "${maker_blastp}" \
-max_target_seqs 1 \
-evalue 1e-6 \
-outfmt 6 \
-num_threads 28
# Functional annotations
cd "${wd}"
## Add putative gene functions
### GFF
${functional_gff} \
${sp_db_blastp} \
"${maker_blastp}" \
"${snap02_gff_renamed}" \
> ${put_func_gff}
### Proteins
${functional_fasta} \
${sp_db_blastp} \
"${maker_blastp}" \
"${maker_prot_fasta_renamed}" \
> ${put_func_prot}
### Transcripts
${functional_fasta} \
${sp_db_blastp} \
"${maker_blastp}" \
"${maker_transcripts_fasta_renamed}" \
> ${put_func_trans}
## Add InterProScan domain info
### Add searchable tags
${ipr_update_gff} \
${put_func_gff} \
"${ips_dir}"/${ips_name} \
> ${put_domain_gff}
### Add viewable features for genome browsers (JBrowse, Gbrowse, Web Apollo)
${iprscan2gff3} \
"${ips_dir}"/${ips_name} \
"${snap02_gff_renamed}" \
> ${ips_domains}
# Create individual GFFs
awk 'BEGIN { print "##gff-version 3" ; } $3 == "CDS" {print}' \
${put_domain_gff} \
> Olurida_v081-20190709.CDS.gff
awk 'BEGIN { print "##gff-version 3" ; } $3 == "exon" {print}' \
${put_domain_gff} \
> Olurida_v081-20190709.exon.gff
awk 'BEGIN { print "##gff-version 3" ; } $3 == "gene" {print}' \
${put_domain_gff} \
> Olurida_v081-20190709.gene.gff
awk 'BEGIN { print "##gff-version 3" ; } $3 == "mRNA" {print}' \
${put_domain_gff} \
> Olurida_v081-20190709.mRNA.gffRESULTS
This took ~5.75 days to run:

Output folder:
The important files:
- Olurida_v081_genome_snap02.all.renamed.putative_function.domain_added.gff (2.9GB)
- GFF file with all contigs annotated with putative functions and functional domains.
- INCLUDES SEQUENCE FASTAS AT END OF FILE!
- Generated with one round of MAKER gene prediction, followed by two rounds of SNAP ab-initio gene prediction.
- MD5:
f54512bd964f45645c34b1e8e403a2b0
- Olurida_v081_genome_snap02.all.maker.proteins.renamed.putative_function.fasta (1.1MB)
- Annotated proteins FastA file.
- Generated with one round of MAKER gene prediction, followed by two rounds of SNAP ab-initio gene prediction.
- Olurida_v081_genome_snap02.all.maker.transcripts.renamed.putative_function.fasta (2.9MB)
- Annotated transcripts FastA file.
- Generated with one round of MAKER gene prediction, followed by two rounds of SNAP ab-initio gene prediction.
All the GFF files have been added to our Genomic Resources wiki (GitHub).
CDS GFF:
- Olurida_v081-20190709.CDS.gff (1.3MB)
- MD5:
eaf22c9868577539238a1b4c378e9200
exon GFF:
- Olurida_v081-20190709.exon.gff (1.4MB)
- MD5:
748d596b07f1b2b18c567494f7d1c5b3
gene GFF:
- Olurida_v081-20190709.gene.gff
- MD5:
6ec24727d92cc095ece0c371eb3b0c6b
mRNA GFF:
- Olurida_v081-20190709.mRNA.gff
- MD5:
ba915ec3a59ee6ff3b7d5e37b5d0463d
A quick grep -c ">" Olurida_v081_genome_snap02.all.maker.transcripts.renamed.putative_function.fastareveals:
- 32,210 proteins/transcripts
The previous annotation (grep -c ">" 20181127_oly_genome_snap02.all.maker.transcripts.renamed.putative_function.fasta) yielded:
- 24,680 proteins/transcripts
That’s ~30% increase in transcripts that have been ID’d/annotated with this particular MAKER set up. However, just as before, MAKER doesn’t ID/annotate any potential isoforms. I’ll probably run Stringtie with this annotation to get that info.
Here are some example comparisons in Integrated Genome Viewer (IGV) of the two annotations. Blue tracks are the current v081 annotation and the pink tracks are the original v081 annotation:
Annotations are the same
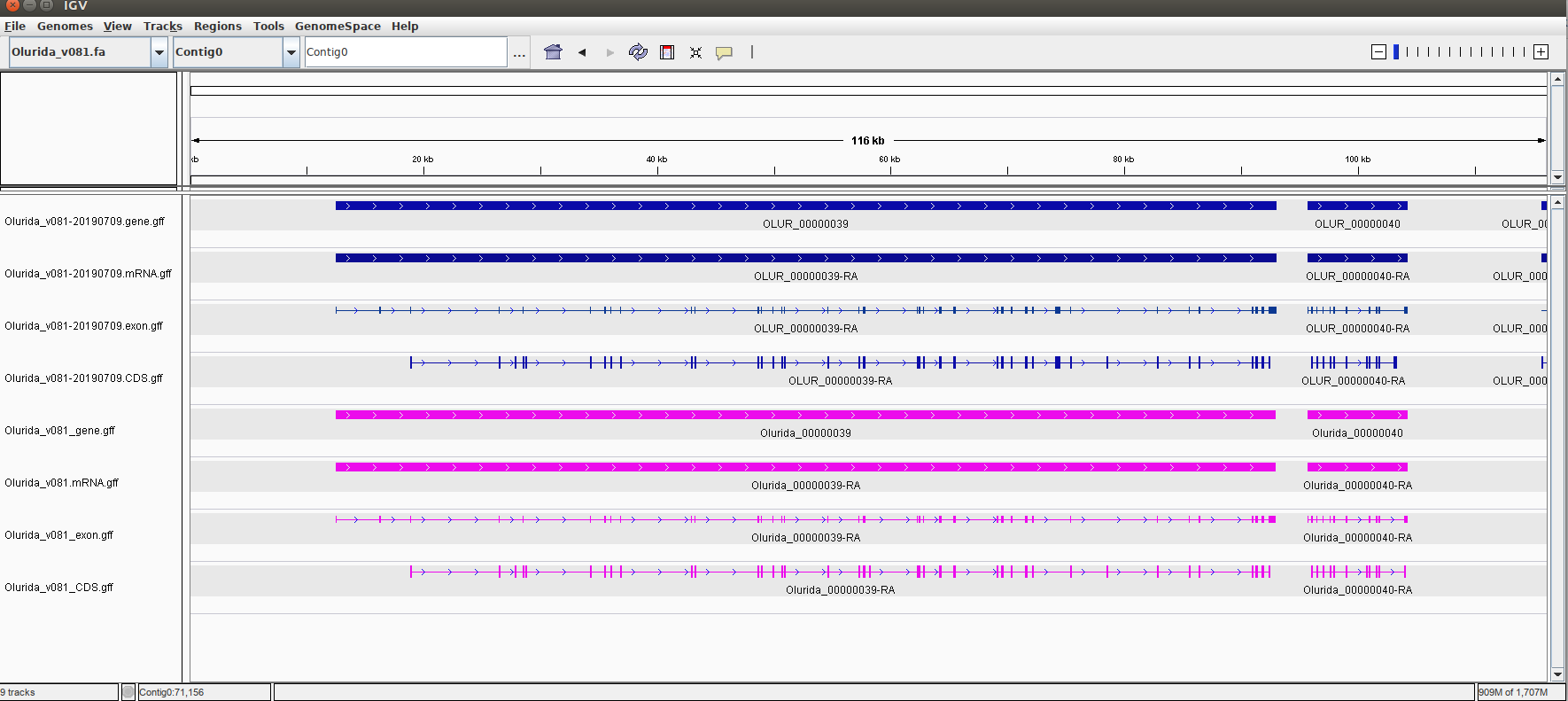
Current annotation has additional features
Also exhibits slight differences in gene lengths
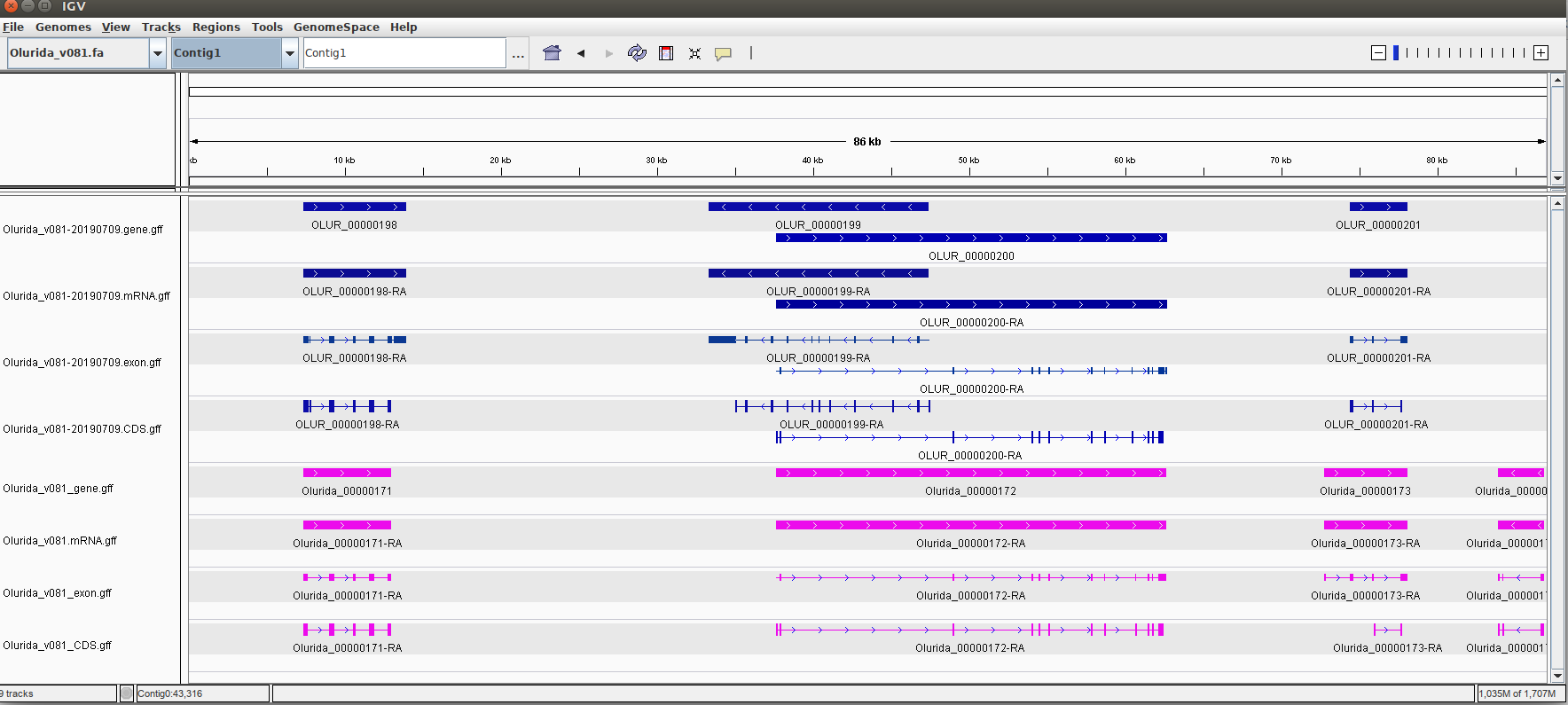
Annotations differ in gene/CDS annotation
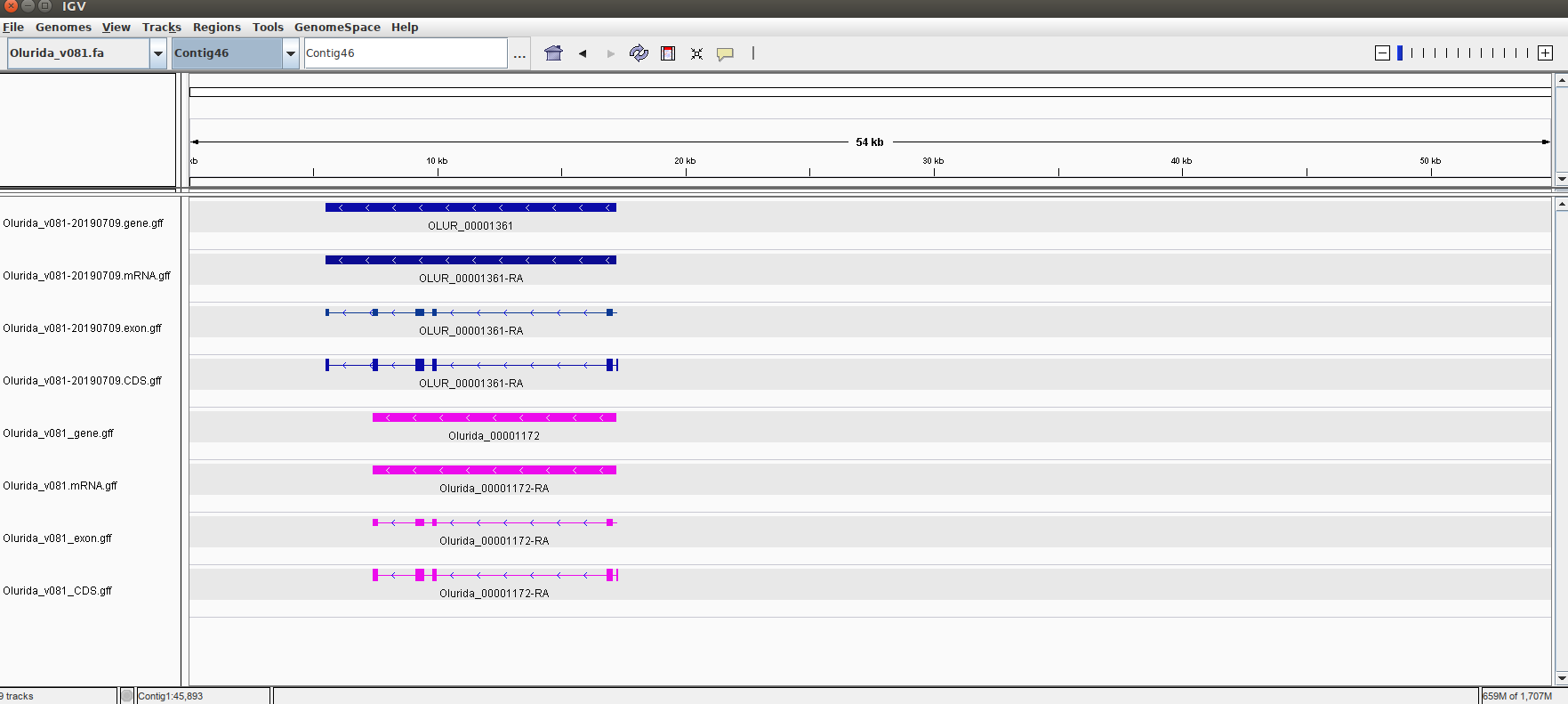
So, what does this mean? Well, firstly, it’s a bit difficult to compare both annotations, as they differed slightly in the way they were run; and not just differences in utilizing a “canonical” transcriptome vs. tissue-specific transcriptomes for the EST evidence. The only way to perform a true comparison would be to re-run the original annotation and make the necessary changes so that all the commands match this, but utilize the “canonical” transcriptome.
Another step we could take is attempting to improve the annotations by adding Augustus ab initio gene prediction to the MAKER annotation. Having a third component for gene prediction would likely bolster results and improve our confidence in the annotations.
Additionally, an aspect that shouldn’t be ignored is examing the Annotation Edit Distance (AED). This value ranges from 0 - 1, with 0 being the highest confidence in gene annotation. Each entry in the GFF files has an associated AED score. We could decide on a threshold and filter out low scoring features; how we’d decide on that threshold is not currently clear to me, though. This paper provides a nice overview of how genome annotation works, what the AED is, tools for annotation and gene prediction, etc.:
Finally, we could also use “old school” bench approaches and do some physical cloning/sequencing of regions of the genome and see how the annotations compare to the actual sequencing data we get back, or some RT-qPCRs on genes with two apparent differences in coding sequence features and see if one (or both!) amplifies.