Yesterday’s post ended with me trying to mount a S3 bucket to my EC2 instance using s3fs-fuse.
Waited for the 36GB of data to copy over to new bucket with proper naming (i.e. no capital letters in name). Copying took hours; left lab before copying completed.
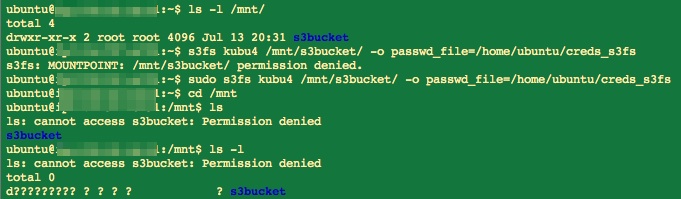 (http://eagle.fish.washington.edu/Arabidopsis/20160714_s3f2_mount_error.jpg)
(http://eagle.fish.washington.edu/Arabidopsis/20160714_s3f2_mount_error.jpg)
So, that didn’t work. The reason that it doesn’t work is that I uploaded the files to the S3 bucket via the Amazon AWS command line (awscli). Apparently, s3fs-fuse can’t mount S3 buckets that contain data uploaded via awscli [see this GitHub Issue for s3fs-fuse! However, I had to upload them via awscli because the web interface kept failing!
That means I need to upload the data directly to my EC2 instance, but my EC2 instance is set with the default storage capacity of 8GB so I need to increase the capacity to accommodate my two large files, as well as the anticipated intermediate files that will be generated by the types of analysis I plan on running. I’m guessing I’ll need at least 100GB to be safe. To do this, I have to expand the Elastic Block Storage (EBS) volume of my instance. The rest of stuff below is fully explained and covered very well in the EBS expansion link I have in the previous sentence.
Don’t be fooled into thinking I figured any of this out on my own!
Expanding the EC2 Instance
The initial part of the process is creating a Snapshot of my instance. This took a long time (2.5hrs). However, I did finally decide to refresh the page when I noticed that the “Status” progress bar hadn’t moved beyond 46% for well over an hour. After refreshing, the “Status” showed “Complete.” Maybe this actually was ready to go much faster, but the page didn’t automatically refresh? Regardless, in retrospect, since this EC2 instance is pretty much brand new and doesn’t have too many changes from when it was initialized, I probably should’ve just created a brand new EC2 instance with the desired amount of EBS…
Created volume from that Snapshot with 150GB of magnetic storage.
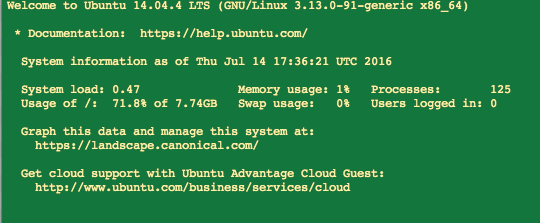
Attached volume to the EC2 instance at /dev/sda1 (the default setting /dev/sdf resulted in an error message about the instance not having a root volume) and SSH’d into the instance. Odd, it seems to show that I still only have 8GB of storage (see the “Usage of…” in the screenshot below):
 (http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_expanded_volume_01.png)
(http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_expanded_volume_01.png)
Check to see if I actually have the expanded storage volume or not. It turns out, I do! (notice that the only drive listed is “xvda” and its partition, “xvda/xvda1” AND they are equal in size; 150G):
 (http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_expanded_volume_03.jpg)
(http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_expanded_volume_03.jpg)
Time to upload (via the secure copy command) the files to my EC2 instance! The following commands upload the files to a folder called “data” in my /home directory. I also ran the “time” command at the beginning to get an idea of how long it takes to upload each of these files.
<code>time scp -i ~/Dropbox/Lab/Sam/bioinformatics.pem /Volumes/web/nightingales/O_lurida/20160223_gbs/160123_I132_FCH3YHMBBXX_L4_OYSzenG1AAD96FAAPEI-109_1.fq.gz ubuntu@ec2.ip.address:~/data</code>
<code>time scp -i ~/Dropbox/Lab/Sam/bioinformatics.pem /Volumes/web/nightingales/O_lurida/20160223_gbs/160123_I132_FCH3YHMBBXX_L4_OYSzenG1AAD96FAAPEI-109_2.fq.gz ubuntu@ec2.ip.address:~/data</code>Details on upload times and file sizes:
 (http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_upload_times.png)
(http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_upload_times.png)
Confim the files now reside in my EC2 instance:
![]() (http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_confirm_transfer.jpg)
(http://eagle.fish.washington.edu/Arabidopsis/20160714_ec2_confirm_transfer.jpg)
Alas, I should’ve captured all of this in a Jupyter Notebook. However, I didn’t because I thought I would need to enter passwords (which you can’t do with a Jupyter Notebook). It turns out, I didn’t need a password for anything; even when using “sudo” on the EC2 instance. Oh well, it’s set up and running with my data finally accessible. That’s all that really matters here.
Alrighty, time to get rolling on some data analysis with a fancy new Amazon EC2 instance!!!