INTRO
This notebook annotated expressed genes with gene ontologies, assigned them to GOslims, and generated corresponding counts of GOs in each GOslim category, as part of urol-e5/deep-dive-expression (GitHub repo).
The contents below are from markdown knitted from 30.00-Ptua-transcriptome-GOslims.md (commit 0b980cb).
1 BACKGROUND
This notebook will perform annotation of expressed genes, as previously determined by 06.2-Ptuh-Hisat.qmd (GitHub).
Briefly, the notebook will perform the following tasks:
Extract all genes from the genome, as GFF and FastA.
Create a subset of only expressed genes, based on gene count matrix.
BLASTx expressed genes against SwissProt database.
Get gene ontology.
Map gene ontology to GOslims and get counts.
Expressed genes were defined as those genes having at least one count across all samples.
1.1 INPUTS
Gene count matrix
Genome FastA
Genome GFF
1.2 OUTPUTS
Genes BED
Genes FastA
Expressed genes FastA
Expressed genes SwissProt IDs only file.
Expressed genes to SwissProt IDs mapping file.
Expressed genes to SwissProtIDs and GO mapping file.
Counts file of expressed genes GOslims.
1.3 SOFTWARE
DIAMOND BLAST (buchfink2021?)
bedtools (quinlan2010?)
samtools (danecek2021?)
Biostrings (h.pagès2017?) (Bioconductor R package)
GO.db (carlson2017?) (Bioconductor R package)
GSEABase (martinmorgan2017?) (Bioconductor R package)
2 VARIABLES
# DIRECTORIES
top_output_dir <- file.path("..", "output")
output_dir <- file.path(top_output_dir, "30.00-Ptua-transcriptome-GOslims")
data_dir <- file.path("..", "data")
# PROGRAMS
blastdbs_dir <- file.path("..", "..", "M-multi-species", "data", "blastdbs")
programs_dir <- file.path("", "home", "shared")
bedtools_dir <- file.path(programs_dir, "bedtools-v2.30.0", "bin")
blast_dir <- file.path(programs_dir, "ncbi-blast-2.15.0+", "bin")
diamond <- file.path(programs_dir, "diamond-2.1.8")
fastaFromBed <- file.path(bedtools_dir, "fastaFromBed")
samtools_dir <- file.path(programs_dir, "samtools-1.12")
samtools <- file.path(samtools_dir, "samtools")
# FILES
count_matrix <- file.path(top_output_dir, "06.2-Ptuh-Hisat/gene_count_matrix.csv")
diamond_db <- "20250620-diamond"
diamond_output <- file.path(output_dir, "Ptuahiniensis-expressed-genes.blastx.outfmt6")
genome_fasta <- file.path(data_dir, "Pocillopora_meandrina_HIv1.assembly.fasta")
genes_fasta <- file.path(output_dir, "Ptuahiniensis-genes.fasta")
genes_fasta_index <- file.path(output_dir, "Ptuahiniensis-genes.fasta.fai")
genes_subset_fasta <- file.path(output_dir, "Ptuahiniensis-subset-genes.fasta")
genes_subset_fasta_index <- file.path(output_dir, "Ptuahiniensis-subset-genes.fasta.fai")
genes_bed <- file.path(output_dir, "Ptuahiniensis-genes.bed")
og_genome_gff <- file.path(data_dir, "Pocillopora_meandrina_HIv1.genes-validated.gff3")
# THREADS
threads <- "40"
##### Official GO info - no need to change #####
goslims_obo <- "goslim_generic.obo"
goslims_url <- "http://current.geneontology.org/ontology/subsets/goslim_generic.obo"
# FORMATTING
line <- "-----------------------------------------------"
# Export these as environment variables for bash chunks.
Sys.setenv(
blastdbs_dir = blastdbs_dir,
count_matrix = count_matrix,
data_dir = data_dir,
diamond = diamond,
diamond_db = diamond_db,
diamond_output = diamond_output,
fastaFromBed = fastaFromBed,
genes_bed = genes_bed,
genes_fasta = genes_fasta,
genes_fasta_index = genes_fasta_index,
genes_subset_fasta = genes_subset_fasta,
genes_subset_fasta_index = genes_subset_fasta_index,
genome_fasta = genome_fasta,
og_genome_gff = og_genome_gff,
output_dir = output_dir,
top_output_dir = top_output_dir,
line = line,
samtools = samtools,
threads = threads
)3 Extract genes as FastA
3.1 Extract genes from GFF
# Read GFF, skipping comment lines
genome_gff <- readr::read_tsv(
og_genome_gff,
comment = "#",
col_names = c("seqid", "source", "type", "start", "end", "score", "strand", "phase", "attributes")
)
# Filter for gene features
genes <- as.data.frame(genome_gff) %>%
filter(type == "gene") %>%
mutate(
chrom = seqid,
start = start - 1, # BED is 0-based
end = end,
gene_id = sub("ID=([^;]+);?.*", "\\1", attributes)
) %>%
dplyr::select(chrom, start, end, gene_id)
str(genes)'data.frame': 31840 obs. of 4 variables:
$ chrom : chr "Pocillopora_meandrina_HIv1___xfSc0000716" "Pocillopora_meandrina_HIv1___xfSc0000716" "Pocillopora_meandrina_HIv1___xfSc0000716" "Pocillopora_meandrina_HIv1___xfSc0000716" ...
$ start : num 886 7304 21621 25312 34770 ...
$ end : num 6811 12239 23112 26016 39392 ...
$ gene_id: chr "gene-Pocillopora_meandrina_HIv1___RNAseq.g29951.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g29952.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g29953.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g29954.t1" ...3.1.1 Write genes to BED
# Write to BED
write_tsv(genes, genes_bed, col_names = FALSE)3.2 Create genes FastA
"${fastaFromBed}" -fi "${genome_fasta}" -bed "${genes_bed}" -nameOnly > "${genes_fasta}"
# Create FastA index
"${samtools}" faidx "${genes_fasta}"
head "${genes_fasta}"
echo ""
echo ""
head "${genes_fasta_index}"index file ../data/Pocillopora_meandrina_HIv1.assembly.fasta.fai not found, generating...
>gene-Pocillopora_meandrina_HIv1___RNAseq.g29951.t1
TCATCTGGTAACAAAGCTTGACTTAATGGTGTAGGACAAAGACATTGGTTTCTTTTTCCTTCCTCTCACAGGTTCAGAGATAGGTGACTACAGGGAAAAAAAATTCACATCCAATGTGCCACTTAACCCTTTAACTCCCATGAGTGACCAAGACAGAATTTCTCCTTACAATATCAATACAATATCAACCAGATAAGTGTTGAGAACAATGAAAATCTCAATTTGGGGATGATTAGTTGATCTAATACTAAATTCTCTGAACTAACATTATCAGAACTGTATGGTTGACAGTAAGGAGAATTGCAAATTTGATCCAGGAGTTAAAGGGTTAAGCAACCTTGTACCCAAACTGTAATTGCTGCTTATGGTGATGAATGTCAAACAATAATAAAAAGTGAAGTGTAAAAGTGTAAAAGTGTAAAACCTGCAGTCAAGTGTTAACCATTTAACTCCCAGATGTTATGAACATGAAATTTCTCCCTATAACACCCATACATTATTCAGCAAAAAGGTAATGAGAATATTCGAGCTTATCAGGTAGAAGCGGCTATCTTGATCTAACACCACGTTCTCGTAACTAATTTACATGGAAATGTGTAGCAGCTAGAGGGGAGAATTAAGAATCAGATCTTGGGATTTAAAGGGTTAAAGACAAAATAAAATGATCATGAGATGCTTTCAGAGGCTGTTTTTGCAAGAAAAGCTGCTTAAGACTGCCACTAACTCAAGTGACTGACCATCATATTATAACTGTATCATTATGTATTTATTAATATATTGTTTTAATTACAGATGGCATGATTACTGGAGCAAAGCCTTTCCATCAACATCCTTTGCTATGGGAAGAACCAACTCAAATCAAGATTTAGAGTCAATTTGTACTTAATTTAAAATGAAAATAGAACAAAAAGGTAACCCTTCATGTAAAATCTTTAGCTTACATCCTCTGTATCTGTTTTATCTGTTGTATCTGTGTCATCACCAGTATCCTCTTGCCTTTGAAATAACACATGAAAAGAGAGCCTCTTTTTTAATTTCATTATCTTAAGTGACAAATGTCATCTCATTTCTTTCATTAAAAATTAAGCCATCATTATTAATTAAAAGCAATTTTCATCTAAGTGCCCCAAAGTAATATAGGATTGCCTGGGTTTTGCTTTATTTCACAACATGATCTGTGGCAGAAAACTCAATTGACATGCCACTTTCCTCAACCAATCAGATACAAACTAAAACCATTTTTGACTAGTTCACTGGCATTTTCCTGAACATTAGACATTTGGCTTGTTTTGTTGTTTTGGATCACCTTCTTGTGATATTCTTTCCAATTGACCATTGGTATTAACTTTGATTTGGTTTTATGAAGCAAAATCAAAATGCATTCTCACAGTCAATCTATTACTAAAGTAACTGCTTTATACCTGATGGTTGTACCTTTAGATTTTCCTTTATTTCTGTTGGCTAAGTCTAGTGATTCATTATTACCTGGGGAAAAGTATAATAATTATATTATGAGAAAAACTGCGACATATCTTGAAAATTTGAAGGTTAATATAATTAAAAACAAAGAAACTAGAGGCAAATCTAATTTGCAATGAAATTGAGTACCAGTATTTCTGTTAACAAGTGAAAAACTGAAGGTTCAACTTTGGATGTCTACTAAAGATTTCTGGTGTGCTGGTCAACTTTCCAAACTTATATGCCTGTAAGGCAAAGTTTAGATTTGTCTTGTGAGAGAAATTTGCTGTAGGCTAAGCTGGTGTGACACTTTGGAAACTCATTACGATTTACGTTATCAACTCAGTTCCTTTAGAAAATTACCCCTAATAAGCTAGTGTGGAAGTTAACATTAAGAACTGCAGGCAAGAGAGCTGACCAAGCATAAATTATTCAATGTCACATTTTTTTTGGAAAAGTTCATTTTCCAATCAAGGAAAGTCATGTAATAGATTTATAAGAAATAACTATCATAAATTATTATTTATTTCATTATGTACACTTTACCTTGTACTGGCTGTGAAGAAGCCTCTTTTACTGCAGTATTTGCATGGATATAAACAAATAAAGAATTGTTATCATTTTACAAAATCAGAATTCCATCTACAGTTAACACAAGGTGAACAAACCTTGCTCCTTCAAATGCCTTATCTTGCTCTTCTTGTCATTTAGCACTGCTGCAAACTGCAATTACAATAAGTAATAATAATAATAAATAAAAAATGATTAACAATAACAAATCTTAACTTTCAAATGGCCAAATACCAGTAAATATCAAAGCAACCCTTTTAAGTCTAGAAGTGCCTAAAAATAATTATTCTAATAATATGAATACCTTTTCAAACACTTGCTAAAATCATCACAAAAAATTCATGATAGACAGAGACTCTGAGATCTTTGGAGAGGAAGAGCTGAAAACATGCTCAAGAACTGGAACGAATCTCCTGATTACTGATAATAAAAGTAAGGTCACAGCCTTAATAACCTTTTCAAATAAATCTTTCTCCATTTCTTCTTTGGCAGTGACACATTTCTCAAGAAGCTGAAAAAATATAATGTTAAGTTAATCAAAGTGAATAAATTAATAAATAATTATACAGTTATTGTATAGAAGTAGAGGTTCAATCAATCATTAAAAAAAACTATCCAGTCAGTCAATCAATCAGTCAATCTCTTTAGATTTAACCCTGTATATCCTAAGATGAGAATTCATGTTCTCTACACTGTTCCCTCTCTACATTTCTTATGGTACCAACAAGGAAAATCAAAAGCTGCTTAAATAAATGATTATTTGCTTTGTTCTTATGACCTTTACATTTGATTCACGAGTGATACTCTTGAATGCCAGTAGAAATTAGAAGTCAGGTCACTCTTAAGGGTTTAAAGTGTTAAATAAGACTGCTAACCTTCAGGGTATCTTTTCTCTCCGAAGATAATCTGGTATTGTCTGATCTCAAAGATGACATTTCTTGCTAAAAGATAATAAACATACATGTATGACCACATGAACAAGTTGCCAATAAAATCTTCTGGAAAAAATAGCTACCAATCTGCTATTTTTTATCTTTCATTTTCACAAGTACAATTATTGCAATGGGGATTACATTAATTAGAGTTCTTGAAAAAGAGACCTAAATTATGACAGTTTATGCCATAGCTTAGCGGTTGGTAAGCTGGAATTTAAATGGCTTGCATAAGTCTATATTCATTAGCTCTCGCCTGATCTTTATGTTGTGTTCTTGCACAACACACTTTAGTCAGAGAGCGTCTCTACACCCAGGTGTATAATGGGCACTGCAACTTATCAGTATACAGTTAGACAAATTACAGTGACAGGGGGGGAGAGGGGGTGGCTCTACTTTGTAACTTAAATGTGCTAGTGAAACTTAACCCTTTAACTCCCATAAGTAACCAAGACAGAATTTCTCCTTACAGTATTAACACAATATCAACCAGATAAGTGATGAGAACAAAGAAAAATATCAATTTGGAAATAATAAGTTGACTCAATACTAAATTCTCTGAACTAACATAATAATTGTATGGTTGACAGTAAGGATAATTACAAATTTGATCTGAGAGTTAAAGGGTTAATGGACTCTAGAGGATGAAGTATCATGCAGCCCAGGTCTATGAAAACAATTGCCATCTAGTGCCATTCTATATCTGCTAATTTTATACTCAGGTAACAAAGAGAGCATTAGTCATTCATTTCAGTTTCATTTAAAAGTAAATTACACATCAGTTACAATTACCTTTAACTGTGTCATCTGGTTTACAGCCAGATCAAACATGTTCTTGATTACTTGAACACTGTCACTAACTTTTGGCAAAGTCAGAGAACCCAGTTGAAACTGGAATGAGACAGAATAATGTATAACTGTATATTGATTTAAAAAAATACATATCTTAAGTCAACAATAAAGTGTCATATACATGTATGTGTTAATAAAATTCAATCTTATTTATGCAGTTATTAAATAATTATATCTTTAGTTTATCTAGGCCTTAATATATCCCCTGTGAACACCTTGAATATACATTAAACACTACTGTTTATGAACAATACTAAGTCTGTAGGACTTTTGAACTTTTCACTACCTTAACACCATCACCAATATGCATCTTCCAAGAGAACTAAAAAGCAAAAAAATAATTAGAGGATATCTCATTATTTGTAGTTTCCCTCAAGTCAAGTTGCTGACAATCCTGCTAAACCAATTAACTGGTTCTGTTTTCCCTAACATTGTATTCATACCCAGCATACTTTTCCCTGCCCTTCTTCGTGTTATTTGAATGGAAAGCTAAATTTTTTTTAACTGGATAAAAGACCCTTTAAGGTAAAGTATTTGGACTTGAGTATTGAGAAATTAGAATCTATAGTAGGTTGTATATAACATTTAAATTTACTGCTTCTCCTTCTGGCACACATATCAATAATATATTTTGAAGATCTTACATGCTTAGTTTGTAAATCACATCATGCTGTTTTAGAACCTCCATTATCTTTTTCCAGTGAGAGTTTCAAGCCATCTTGTACTTTTAAAAAAGCTGGGCTTACAAAAATTAAATATATATTAACTTATGTTGCTGTTTCTCTTCTAAAATAAAACAAAAATCTGGCTTGTGGGAACAAAGCTTTTTTCAGCATCTCACCACATCAAGTCTGTATCAATCACTTACCATTTCTATTTTTATCGAAATTCAGGAAATGGAAATAGCTTAATCAACTACTCAGTTTTATTCCATCTTAGTCATTTGTAACAGATATCTAAAGATACCCAAATTTAATTAATCAAAAATGCCTCAAAAGGTTTTATCCAACCTGTAACTTTGTCTCTTTAGGCTTGGCTTGAAAGACAAAATTATCCTGACTTGTTGTCTGGCCTGTCAGTGCTCTGCTTGTTTGATCAGCAAATTCAGTAACACTCATATCAGCAGTCTTTGCCATAGATTCAACAGTCAATGAATCAACTTGAAAAAATAAACAACAGAAGTAAATCCTTAAGAGTGACTAGCATCTAATTTCTCCTCACAGCATCTCCCCTGAATTGCACATTAAGTTCATGATAACAATAGAAATAATCACCAACTAAAGATGCTGTTGATGTTAAAAATGATCTCAGTCATCACCTGAGGTTCAGAGCCATATTTTCAATTTTATCTAAAGCTGCCATCAGTCACTGTCACAGTGAATATCTCAAAGTAGAAAAAAACAAAAGCACAACAACCAAAAAATAAGGAATTGAAATCATATTATGATAAATGAGGAGAAGAGCACTGGAACCTTCTGTAATATAGCATATGTTTCCAAAGGGGTTTTCAGCATGGTTTATGGCAGAAAAACTTCACTTCCTAGACTTTTAACTGAATAAAATTAACAGCAGCCAACATGATTGGCTGTGAAGGCAAAGTGAATACTACAACTGTCACAAACACAGACAGGGGGTATCATGGTCCATGGGGTGGGATTTTTTTTTAGACCTTGTTTTCAACTACTAGTTCAGTAGTGTTCATAGCTGCGAGGATCGCTTCTATATTCGTTTCTTCAACCGCAGTGGACATATATGATTTTCATATATTTACAGCCATTATTCAGTTAAACTTGTTGTCATTTTCCTAATTAGACCTTACCTGAATCAGGTTGTCTGAACTAATTACAAAAGGAACCAGTAAATTGACTACCAAAAATGCAAGCGTATTGCCAATATTTCCAGATTCTGAACAAGATACATGGCTGAATAAAGAGGAATCCTTCATGAAGATGATAATTGGTTCCATATTTTCAGACTATTTACCTGTTTCGCGCCAAACGTGATCGCCATTGCAAACGGTGAGGTCGAATCCATCTTTGCCTTGGTCAAATAATTCTACAAGAAGATAATATTTAACATCTTCAGCTGTGATTCTGGTAAAATTCTGCGGCAT
>gene-Pocillopora_meandrina_HIv1___RNAseq.g29952.t1
ATGGCGAATCTTTTTGCAATCGCTCTTACCGGAGACAAACGAGTATTTCAGCCCGGCGATACAATTTCTGGCGTGTTGCTTCTGAATACAAACAAAGAAATTAATCTGAGAGGTGTACGTGTTGAGCTGCATGGTGTAGGGCATGTGCGTATTCGTTCAGGTAAAGTCACCTATGCCAGAAGAGAAAACTATCTGAGCTTTCAGTCAATTCTTCTAGGAAGAGGTAAGATTTTCTCCGTGTTATGAGGGACTACTTTCAAAATTTAACATTTTAAATTAGCAACGTACTGGTTAGACTTCCGACGAACACAAATCAGTCACTCGTCTTTCAAAATATTCATTGTTGTAACACTACCCTGAGATCTGAATATCTTTTTTTTAACAACTTTTTGCCGGTAAGTATGAATGTAGCCCTCAGTGTGAAAGGGTTTCGAACAGTGAAAGAAAACCCAGCCTTTGCAAGCTTTCGCGCTCGAGCCTAATTTCATTTTCGTATCGTTAAGTAGCTGCTAATTTGAATTCGGATGGGAAAATGCGGGAGTAGTCCAAGTTCTGTTGTTTGTTTAATATTTTTTTCCATTAACTTAACGGTTTCCTTCCCCACAAACGATCCTCCTGAAGAAGTGAATTGCTAAAAAGGGATTTTCGTCTCAAGAAACACGAAACAAGACAAGCATTTTTTCGTTCCAAAGTCCAATTAATTGAGTCATTTTCAGCGTTACAGAAAATTTAATTTAAATTAAAGAAAATGAAAAACTGTTTGATAATGTAGATGCGTTACCCCACAAATTGATGTTTCGACCGCGATAGTGTGCCAACTCGATTGTTTATGTCAACTTTCCCTGTTTGATTAGTATGAGGCTTAGTGCCAGACCCCTCGGCGGCCTCGCACTTTCTCGCGTGCTCTGGAGAAAAGCGCTCTTACTCAGTTTTTCTGACGCTTCTCAATAAACATCTTTGTGAGAGAAAACTGATTAAATTTTCTCGTTTAAAGATGCAAAACGAAGATTATTTTTTCTTTGAAGCACTAGAATCCCAAATTCAAATATTAAAACAACAGATGCGTTTTCTTCTAAAAAAAATTACTGTCTCCTTAAAGGCCCATTTTCAAGCAGCCATAACAGTAAATCAAAGAGATAAGTAGCAGGCAGATCAGGACTCCGAAAATTCTCAATTTGATTTTTCATGAGAATGGCAATAGTGACACACTAAACATTCAAAATAGATTTCAGTGTCTCCATTCCCTTTTTCACCATTGGACATAACTAAAAAAGTGGAAAGAGGTAGAATCACGATTAGCTCAGTTTTCTCACCCTTTTGATAAGGATGTAGCTATTCGATAACTTTGCTTGCTTGGAAGGTCGTTCTTCAAGAGCTAGATGAAATTAAATTATCTTTCTGGACCCATCAGCGCTTGGTCGATCGAATCTCGAGAGAAAAAGGAAGAAAACCCCGACAGTTAATACTGGCGAATAGGCGATCAATCAAACCAATAAAAGCGCGTTACAATTTCTTACATCAACTCCTCGGCAGCGTTTAACATATTCTGAAAATATCTGTATTTATTAATTTGACCTTAATCTTATTCATTTCGATCCAAACTAACGTTTAATTTATTTTCTTTAAAGCACCTTTCCAAAACGGAATTGACGTAAAGCTTCAACCTGGAAACTACAATTTCCCTTTTCAATTCCCACTTCCTGTGTCCGCATTACCAACATCATTTGAAGGTACCTACGGTAGTGTACGATATTGGTTAGACGCTGTGGTGGAGCGACCGTGGAGAATTGACCTCAATACCCGCACACCGCTAGTTATTGTCGAGCGCGTGCAGACTAGGAATCCAGAATTCCTGGTAAGTACTGGCTCGAAATGTGTTCCAGGCCCAAGAGGGAACTCATCTAGATGTGGTTCGAGGGGGGAGCCACCACAACTTATCTTTGCGCATCGAAAACAAACCCAAATTAGAATCCCTTACATTTTCGTGTCCCCTAGTGCATGAGGCATTGTATAACGGACTGTCTTTAGTCCTGAACATGATGTATGATCACATTCCTGATTCTTTCTTTACCCTATGACTCTTTGGTTCTATTGAATAACGGCATATGCTGCACGTTTTCCTAAGAAGAAATGTTTGATTTTATAATTGATTTCACGAAGGAAGAAAGAAATCAAAATTGAAAGTCCTAGAGTAATCATGTCGGCGATCGCTCACCACGTTTTGGATACTCTCTGATCATTTGTTGTCGACAGGAACCAAGAGTGAAACAAGAAGATCGTATGTTGGGATGGCCATGTTGCCCTTCAGGTCAGCTGCACACCAAAGCCCGCATAGAACGTCTTGCTTATTGCCCTGGTCAGGAGGTCAAGATATCTGGGCATGTTAATAATGAAAGCAGCAAAACAGTTATCGGTTTTGAAGCGCAACTTGTACAGACAGTGCTATACAAGGCACCGGAAGGTAAGGATTAACTTTTACACCAATAGAAGCGGCAAGCATCTAATTTCTCCTCACAGTGTCGCCTCTAATTCAAAGTGACATTAAGCTCATGAAAAAGAAGCAAATGATCGCCACGAAAGGAGCTCTCGATTTTGCAACCAATTCTCTTTTGAGTACCGAGGGAAATGAATAGAGAGGATTATGGAAAATTGCATACTGATCTTAGGATGTTAGGGGTTAAGGAATGAAACATTGCTTGAACAATTTGAAGGAGGGATGAAGGGGCAGGGAAATTTCTACTCCCTATCTACGGGCCTATCTGACCTCACCAGTTATGTGCCGTGTTTTGTTCTTCGTTCATAAAAAATATTTTTACAATCTTTTTAACTCCCAATGTCTTTTTGCTGATTCTCCACACTGTCAACCATTCATCCCTAAGCCCTCGTAGAAATTAAGTTCATTTATCGGGAAAACGATGATGATGCTCGGATATTTGTGTGGTGGCTTCATTTTTGAAGGGACTTTGATTAAGTTTTGTCTGTCTGCCTTTTTGCCTAGCTACAACACGTAAAGTAACAGAGAAGCTTTACATCCTAAATAAAGAACAAGAACTAGCACCTGGAGATCAAACCAATGTCGAGCTTGATTCTTTCGTCATTCCACCTGTACAACCAACGACAAAAGGATTCGGATGCATTGACATTTCGTACGCAATCAGAGTAAGTGCTTGTCTCACAGGGTATAGTTGAAGGGGTATAGTTCATGGCCAGAGTTTTACAGATATTGTTCCTTTGCGTTTTAAGGCTTCTCCTTGGAACTTTTTTTTCCCGATGAGTCGGTATCGCCATCAGTAACCTTTGCCATTGACAGCATTGTGGGTACTTTGAGCGGCACAGTCGCGAAAACGCGCGGTGAAGCCGTGGGAAGCTAGGGACATGAAATAGTTTCTCCCCCCCCCCCCCGCCCCCGTTTTCCGTCCCAGGCGTCTCTTACTAATCTTCTAGCTCCATCGCTCATTACTAAGGCTTTAAAGTAAACCCAGGACCGCCAGCTACCTAGGAAAATTAGTAAGGCAGCAATGGCGCTTTTCAGCTCGAGTAAATACAATGTAAGTCAGCTGAGCACTAATGCGTGCAACTTCCAGCCCCTTTTCCGACCTCTTTGATTCAGTTGACGTAAAACTACCGCGGGAAGAAAAACTCATGTTCCATGCTGCTTTTCTGTTTACTTCTCACTTTAATTGTTCTCCTTCCTTTTATGAAGGTAAACTATCCGACACAGTTACACCTGATAAATGGTTCTCTCCAATGTCAATTCAACACTTTTTGACTGTTAATTCTATGTAGTTTAAAGTACGCGTGAAGAAGGCCTTCAACACCGAAATAATCTTCCCAATTGTGATAACTACGGTACCTCCTAGCGCCGAGCCCTCTGTTGATCCAGTCTTGAGAGAGCACATCTACATAGCCCTTGCTAATTACCTTGCGTCACGTGCTGCTGCAGAACTAGACAATGATGCACAAGAAGCGACTGAGGGAGAAAGGAACACTGTTTGGGATGGATCACCTACTCCAGAAGCCGATCGTAAGTAAATACAGTGGGAGTTTTCGTTTTATTTGAAACTGTTGATTCAAGAAGTAGAATCCATATTTCGCATTGCCTTGTTGTAGATCGCAGAACACGTCAAAATGGTAAGGAAATATGAGTGATGACGTCCTTATGATATTTTGACGGCTACGGCGCTGTAAACTTGACAAACACGCAGTCGAATTGTAATTTTTTATACAGACGCGATTAAAACATTGATTACTATTATTACGACTATAAGATTATTCTTGTAATAGTTATAATCAATTGTTTTCACTTTTGTCATTTTCATCATTTTTATTAGTATTTTTATTATCGTTATCAATATTATGTGATGGGTACTTATCACTCTTTGTGTAATATATAGATTTAGCCAAGCCTAAAGACGGAGCTTGCATTTTTTTCCCCGCACGTCTCAAGGGCACAACGCCTTGCCCCGGCCAGGACTAGAACCCGAGTCGTCCGACTCGGAGCCCAGTGCACTGACCATTGGACTACTGGACAAAGCCGTGGCGTTTGCGTGCCCGCGGTACAGTTGACCACGCATGTTAAAAGTAGCACCTTGTACGGTCGTACGGTCGGACATCCAAATGTTTTCGGCTTGATGGGTTACTACTATTTTGTATAACTATGGGGCTACGCTCTGCGAGCTCCGCTAATATTCAGCTTAGTTGTTGGATAAACTCAAACAAAACGTAGTTCAAACACGGCTTTAATAATAAAAACTCAGGAATGCGCAGGTCTTGCAAGTAGGATTGTTTCGTACACAAAGTTGCCATAGCGGGTTTTATTTTGTCACATATTATCATCTCGAACTCTGCCTGTTGTTTTTAGGTCCGCCTGACGTCAGAAGCAGCGACAGACGTGGGTTTGACACTGGCCAGCCATATCAATATACCAGAATATAA
>gene-Pocillopora_meandrina_HIv1___RNAseq.g29953.t1
TCACCATGGTGAATTGCCACGACTAAGTTCTCGGAAACGATCAAACCAAGTTTCCCTCCTTTCATTTGGACAGAGATCTCGGTAGAACTTCGATCCAGCTACTTCAATGAAGCCAACAAGGCACTCGGAATCAGCTATATTGTCGAAGCCTGAAAAGTCGAATAAATGTGATTGAATAGCTACAGATACGAAACACAAATTTGAAGTGTAACAGGAGTAACTGAAACCGATTGGATGCATATGTCAGTTTAATGACGACTACTCCTTCCAAACCTGGATGGATCTAGAGAACTGGAACTTTAATATATTTTGAACTGGAACTTGTGCTCTCTTCCATTTACGTATGAAATGCATTGTACTTAAGTGGAGAAGATTATTCAGTTTAGACGTGTTTCGTAATTTGTTCAATGAAATCATAGTGGGGCATGCTTTTCCATAACAGTTTCCTTTCGCCAACAAATATTCAGGCAATGTGAAAGTCCACTAACATCTCTATTTTAGTTCTCTAATTATGCTAGAACAACTAAATATTGTTCAATTGTTTTTTTTCGACTTCATCGTAATTTTATCATAAGCTACAAAAAATGAGCTCCTATTCAAAACGAAAGGAAATTATAATTGAATTGAATCAGCACGGGAATCCTTAGGAGCTGCATCATTAACCTGTTGTAATTTTATATTCTAGCGATAGATGCGGACGTTGAAGTGGAAACGAAAGGAAAAGAATCGCTGGCTAGGGCTTATTTCTTGTGATGAAAAGTAAACCTTAGGTACTTCGCAATGAGCTTATAACTAATTTCTCTTTAAGTTGTTTAGCTCAGAGACAAGTGTTGACTTACCATGTGTTTTGCCGTCGAGGACCAAACATACGTGACATCCGTTATAATCCCCTTCTCCCTCAAGGAGATCCTTTTCATTTGCGTATAACATCAATCTATCTTGAACTTCTAACCAAGCTTGAGGGTTAGTTGGTTTATTTAACTTCTTGTTTACAAATCCAACTCTTGGTTCTGATGGGTGAAAAAGAACGTTGTCGGCCCCCTCGATAACGTTCTCGATTATCAGTCTCTCGATTATCAGTCGCTCGATTTCGTTAACCTCTCTCTGCATTCCATCAATTGGATAGTCCCTAATGTGTTGATCATTATGGGGCCAATTGCTGAACTCGTTTCTTCTTTCCTCCAAGATAGCGAGATATTTGTTTGCATTTACACAAAGATGAGCATGATAGTTATGCCTCGAACTGTACCATGTACCACAGTGCTGGGACAAAACAGCCCTTGATTCATCAAGAGAGTAATTATTGACCATCTCCAGGGCTAAGCTGATTACCTGTCTTTTTTGATCATCGCTTAGATCTTCGTACGTCCTTGACAACGTATCGTCTAACACAATAATGAAATGAGGTCTGGCCGTGTAGCAGTCAAACTTCACCCTGAATGTACCGTCGTCGAGCAGACTAAAGTTATAGACAGACGTTCGATTTTGCAT
>gene-Pocillopora_meandrina_HIv1___RNAseq.g29954.t1
TCATGTAGTGATTACTGATTCGAAAAACAAAAGTTTCACAATGGGTTCGTCCGTCACTTCACAGCCCTCAGAAATCAGTCCTGTAAAATCTGGATGTAGGAATGAACAAAACAAGAAAGCTATTTGTAAATGCGCTGAACTTTGTGGATTTATGGCTAAAAGCTCAAGAGGAGTGATTCAATATTTTATTTTAGCTTTTAGCCGTCAATCCACAAAGTTTAGCGCATTTACAAATAGCTTTCATCTCACACCCAATTAATGAATGAATTATGTGCTCATGAGTATTGACCACCATTTGAAAGCATAGCTATTAAGTACCTCTTTGTGTAAACGTATTGGACTATTCCGTTAATTCAAGGTAAAGGAGAATGATAATATACGTGTACATGTTTTCCTCTAATGACGAACTTAAAAGATATGCTTTTAAGTGGTGGTCAATATGAGAATCGCTGGCTAGGGCTTATTTCTTGCGATAAAAAGTAAACCTTAGGTACTTCGCAATAAGCTTATAACTAATTTCTCCTTAAGTTGTTTAGCTCAGAGACAATTGTTGACTTACCATGTGTTTTGCCGTCAAGGACCAAACATACGTGACATCCATGATAGTCTTTGTCTTTGTGTCTTATCTCGTTCTGCTTTGCTTTCCTAGAAGAGCTTTTTCCGCGACACGAAACGTTCCACCGGTTCACTGAGTGTGACAGCAT
>gene-Pocillopora_meandrina_HIv1___RNAseq.g29955.t1
ATGGAGACGGAATGTTTAGTGACCTACCCGCTGACCTTCCAAGCTGAGTTGTCTCTTAGTATCAACAAAAAGGTTTTGGAGAAGGTATGCCATAAATTTTAGGTACGTCGAGCAGCAGAATTTAAAAAAAGATAGTTTTTGGTACGGTATTCCATAAATGTTTACTCAAGGAGAGTCAGAATTTGAAACAAGCCGAGAAAATTGACGAAAACAGTGTGATTTTCTTTTTGCATTGCAGGGCTCCACTGTTTAGAGGTCTCAACCCTGGATTTCGTCGCATGCTCTCACTGGTGATTACGACCAGTATTTTACATGCCAAAACCAAATCATAGCCAACAAAGGAGACATTGGACATCATATGTTTTACATACACCGAGGCCGGGCAGAAGTGAGCTCATTTTGTTAAACATATCATCAGAAACACGGAATTGCCATTTTTTATAGTTATCCCAGTGTTTCTCCGTGCCGGTTCTTGTTGTAGACATTTCCAGACATTTGATCATTAGCTCAGCTATAAATGAATTCATTCGAGTCACAACCACGCGGCAAAAAGATATATCCTTCAACGTCTCATTTTTCTTCTTTTCCTCAAGGACAACTTTCTCGAAATTTGAAGACAGCCTTACTATCCAACTATCATTTTCACACAGAAACTATTATTCCACGTCTTTGATATGTTTCAAATATGAAACAGGAAACTAAGAAAGTTCCTATTGATCATTCAACAAATGGTGTACGTCATTAGTAACTGAGTCATTCAATCACTTTGAAGCTGAACTAGGTGAAATTATCAATTCGTAACACGATAATTAAGGACTTGGAAGGTTATCTCTCATAAGTTTTCTTTTTTAATTTCAGATTCTTTGTGAAAACGAAAATGAAGTTCTGGTGACTCTTAAGGAGGGAAAGCTTTTTGGTGAAGTACGTAAATACACTTTTGTTTTTTTAAACCAAGCTTTTTTTGTCCCTTGGATATCGATTAAGTTCTTATAATGACAAAAACCCAAGTGTATTTTGTCTGCCTGGATTTAATTGTCTTTGGTTTGTTTATATTTTTGCAGTTTTTTTTTATGCGACCCAATTTAAGTGCACGTGTCTTTTTTTCATTTGCTGGGATTTATTTGTGTTAAGTCAACTTTTCGCTTTGTTTGTTTGTTTCGTCTTTTTAAAAAATCAAACCGAAATCTTCCTTTACATATTTATTATTTTCTTGTTTTTTTTGTTTGTTTGTTCATTTGCTGTTGTTTTTTTGGGTATAACTCCTAGAGGTGAAATAACAAAGTGTTAGGCACATTTGTTCGTTGTTTCATCCTTGGGAAATATACTTATAGGGAAAAAAAACATTCTGTTGATTTTTTATTTATTTACACAATTTATTTACGCAGTTTATAGTTTTTTTTCATTTGACATTAACGTGAAGCAACGTCGAAAAGCAGTCAAAAATATTTTACAAACAGTCGCTATTATTATTCTTTATTTTTCCTTTCTATCTGCATCACTTTCTGGTGAAATATGTTATTCCACATGTTATGGAATTATAAAAAGACTAAATGACTGTTGATAGAATTAAAAAAAAAACAGTGTTTTGAGTTCTGAGGTATAATTTCTTGATGACATTTTATTTGTTTCTTTCCACAGGTGAGTATGGTGTACAATCTCCCGAGGGCTACCTCAGTTCGTGCCGCTTCTCCGTGTGTAGTCTTCCTTCTTGACAGAGTTGATCTCAACAGAGTGCTTAGACATTATCCCGCCGGTACGTTTTTACCAAAACCCATCAACAAATCTTTTTGATAATTATTGTTGATTCACTTGTGCTTATATTTGTGTGAAGCAACCAAACAGTACTTTTATGTGGAATGCGATAAGAGAATAGTATTTCAATTTTTGCGCTAGAATCCAGTTGGAAATATCCGGGGTCCTAGTTCTGATCAAGTCAGAACACTCCTTTTAGACAAGACTCTCACTGTGTTTCTCTCTCTTCTGTAGTATAAGATGATACAAGTAAATTTTCGGGAAAATCTTATAAAATTGCTATCAGATGAACCACGGGAAAGTTCATGTAGGATGAGGGTCACTCAGATACTGTTCAATCAATGAAACTCTTCCTTTCTCGCGTTGCATTCAGTTGGACCAATCAGAGGTGTTGCTCAACCTGATTGAGTTCGCAATGTGAAAAGAATTTGTAGAACTAGTTAAGCGCCCAATCCTTCTAGTTCTGCAGGGGGCATAAGGATGGATGGGCAGGGTTTGACCAGTGATGGGTTAGGATCCCATTTGTACCCCAGCTCAAATTCCACGAAATATTCTCCAGTGGCATGGATCACTAAAAATACGTGGGGCTTTCATTACTGAATTGGTTTTACTATTTTAGTGGCAGAGCAATTGTATTTGACCCTCGAACATCGATGTGATCTGAACAATATTGGAACACTGGGGCATAGGAGGCAGGAAGCAACAAAGACGAATTTTTGGAAATGGAAAACGGAAAAGCTGAGGCCTGGCTACGGCAAAGCGCGGTAAGTACAGTGGTAGGAAGGGGCAGATGTAACTACGCGATTGTATGTCGGCAATGACACAATCGCGTCTGTTTACTGCGTAATACGCAGAATGGAAAGCTTTTTCAGTTGACTTGAAGCATCACCAGACGACTCAGGCGGATTTTTATCGCTTTGAAGGGCTCAGAATGATCCTGAAATGATCAACCCCTTGTTTAAACATTACACGCGATATATGAGTTATCACAATGCCCTTAAATGAGACCAAATACCAAAGTCTAAGAGCAAAATAACTTGTGAAGTGGATAATTTGTGGGAGAGGGATTTTGCAAAGAGTCCAGTTTCTCACTTAATAAGGAAAAATTTCCAATTGACCTTCAACCGTAATCCTAAATTTTTCTGGTTTTTCTATACCTTAAAGTATGATTGGTCCGAAAAGCTGGCCCCACTTTTTCGACCAATTATACTTAAAACTATAGCGAATCTCGTCTTCATTTCTCGAGTTTCCCCGGCTTGAATCAATTTGCCTGTTCTGTTTGCTTTGACATTGGTTTTCGATACTCGATCGAAAAGCACTTCAATCCTATGTTGGTTTCGTCCAATCACGAATGTATTTTCTTTCGTACATAGGACTTTAAAGAGGATACATCCAGTAAAGAAAGGTACCATGCCAAATGATTACAAACTTTGCCGTTACTCATATATAGTCCGGGGTTGAGGGAACACTGAAAGATGAAATTGTCTTGCCCGAGAGAAAAAATCAAGGGGAACGCTAGAGAGTATTATTTTTTGGTCAGGAATCTTGAAATTATCAGTAACGAGGGGGAAATAAGGAGAAAGTGGGGGCGTCTAACCTCAAAAATCCTAGAAAATGATGCTCATTTTAGCCGCGTACGGCTGTTTTCCCCGAACAGATGAGTAGAGCATCAAGGCATGCCTAGCTAAATTTACGCATGCCACATACAGTTCGAACCATGTAAAGGTTCCAGGACAGAAAAATGGGCTTCCATCGTAATTAATCGTGAAATTGCATATGCATGGTATTTCTCGAAGTGGCCTGTTCGGTGTCGTGGCCGACTTTGCTAAATTGCTAAATCCTAATTAATTCAATAGTTATTTCGTTTTCTTACTTGGAAAAATCTAGTTTCGTCCTTCCCACAAATCAACTGCATAAGAGTCCTCTGCTGATAACCATTACTTGTGCTTTTAGCCTTTTAACGAGGTTTTCTCGCCACGTCATCATGCCCGATTCCTGGTTCGCGGTGATCTGGGAGCGACTTCTTCTGTCTGTGCTCCTGTTCATCTGTTTCGTGTACACTTCGTTGCTTCGTTTTCAATCAGCTTGCATGCTCTCGGTTACGGAGAAGGTGTCGGAAGTAAAGCGTTGATGAGTTTTACCTACTTACTGGACGCTGTTTTGGTAGCTGATTTTATAATGAGATTTAACATGGCTTCTGGGACCACTACAGGTAACTAGAGATCTTGAATCTAATATTTTTCTAAAGAAATATCAGATTTTTTTCGGCACTCAGTTGACTGAAAATCATCCTTAGGTCATATTAGCAAACGGTGTAACACACGGGTAAAAAACTGGGCCATAAAATTAGACAACATTTAGCACAAAATGCCCAACCAGCTGAGTTTCGTCAGGCAGCACGATTTTTTTTCCTCCACGACATACACTTTCAGAAGTTTTTAATTGGAACAATGCATAATGAATGGCTAGAAAATAACATCTAAAAAGTTTATTGCGTGTTAACATGTAAATTCAGGACTAACTAACCGGCTAAAGGGGAAAAAGGAACCACTTAACTGCCTTCTAAAAAGAAACGTTTTAAAATTTTTCTTAGTCTGAATATATTCAAACTACAAATGATTCAAATTGAGCTCGGAAGCAGATGTTAAATTCTAGGAGCAGTATTGCTGAATGATTTGTACTGATTTGAATGAGCTTTTCATTTTTTATGATTAGATATTGAAGATATAAGAAAGTCTTACAGAAGAAGTCTGTTATTTTGGATCGATTTACTTGCTATTCTTCCCATTGAGATCTTCGCCCTTTCCCCAAGACGATCATCACAAGGTTTGGCATTCTTTGGCATTCCTACGGCTGAATCGGCTCATTAA
gene-Pocillopora_meandrina_HIv1___RNAseq.g29951.t1 5925 52 5925 5926
gene-Pocillopora_meandrina_HIv1___RNAseq.g29952.t1 4935 6030 4935 4936
gene-Pocillopora_meandrina_HIv1___RNAseq.g29953.t1 1491 11018 1491 1492
gene-Pocillopora_meandrina_HIv1___RNAseq.g29954.t1 704 12562 704 705
gene-Pocillopora_meandrina_HIv1___RNAseq.g29955.t1 4622 13319 4622 4623
gene-Pocillopora_meandrina_HIv1___RNAseq.g10233.t1 12236 17994 12236 12237
gene-Pocillopora_meandrina_HIv1___RNAseq.g10234.t1 2891 30283 2891 2892
gene-Pocillopora_meandrina_HIv1___RNAseq.g10235.t1 739 33227 739 740
gene-Pocillopora_meandrina_HIv1___RNAseq.g10236.t1 408 34019 408 409
gene-Pocillopora_meandrina_HIv1___RNAseq.g10237.t1 9077 34480 9077 90784 Subset Expressed Genes
Only those with at least one read in each sample
4.0.1 Peek at count matrix
head "${count_matrix}" | column -t -s","
echo ""
echo ""
wc -l "${count_matrix}"gene_id RNA-POC-47 RNA-POC-48 RNA-POC-50 RNA-POC-53 RNA-POC-57
gene-Pocillopora_meandrina_HIv1___RNAseq.g10047.t1 697 540 1379 824 343
gene-Pocillopora_meandrina_HIv1___RNAseq.g3015.t1 68 101 114 50 77
gene-Pocillopora_meandrina_HIv1___RNAseq.g23582.t1 464 464 569 283 505
gene-Pocillopora_meandrina_HIv1___RNAseq.g4478.t1a 115 247 307 94 82
gene-Pocillopora_meandrina_HIv1___RNAseq.g10221.t1b 0 0 0 0 0
gene-Pocillopora_meandrina_HIv1___RNAseq.g10221.t1a 0 0 0 1 0
gene-Pocillopora_meandrina_HIv1___RNAseq.g4478.t1b 1917 4712 3555 4597 754
gene-Pocillopora_meandrina_HIv1___RNAseq.g24713.t1 0 0 2 15 0
gene-Pocillopora_meandrina_HIv1___RNAseq.g6293.t1 27 39 106 32 0
31841 ../output/06.2-Ptuh-Hisat/gene_count_matrix.csv4.1 Import count matrix
# Read the data into a data frame
count_matrix_df <- read.csv(count_matrix, header = TRUE)
str(count_matrix_df)'data.frame': 31840 obs. of 6 variables:
$ gene_id : chr "gene-Pocillopora_meandrina_HIv1___RNAseq.g10047.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g3015.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g23582.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g4478.t1a" ...
$ RNA.POC.47: int 697 68 464 115 0 0 1917 0 27 45 ...
$ RNA.POC.48: int 540 101 464 247 0 0 4712 0 39 27 ...
$ RNA.POC.50: int 1379 114 569 307 0 0 3555 2 106 60 ...
$ RNA.POC.53: int 824 50 283 94 0 1 4597 15 32 58 ...
$ RNA.POC.57: int 343 77 505 82 0 0 754 0 0 81 ...4.2 Only genes with at least one read per sample
# Filter rows where all values are greater than 0
filtered_count_matrix_df <- count_matrix_df[apply(count_matrix_df > 0, 1, all), ]
str(filtered_count_matrix_df)'data.frame': 18004 obs. of 6 variables:
$ gene_id : chr "gene-Pocillopora_meandrina_HIv1___RNAseq.g10047.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g3015.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g23582.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g4478.t1a" ...
$ RNA.POC.47: int 697 68 464 115 1917 45 8 5226 27 160 ...
$ RNA.POC.48: int 540 101 464 247 4712 27 27 1358 42 13 ...
$ RNA.POC.50: int 1379 114 569 307 3555 60 75 6860 25 250 ...
$ RNA.POC.53: int 824 50 283 94 4597 58 95 2584 36 93 ...
$ RNA.POC.57: int 343 77 505 82 754 81 102 954 58 74 ...4.3 Subset genes FastA
Only expressed genes
# Get the row names (gene_ids) of the filtered data frame
filtered_gene_ids <- filtered_count_matrix_df$gene_id
fasta <- readDNAStringSet(genes_fasta)
subset_fasta <- fasta[names(fasta) %in% filtered_gene_ids]writeXStringSet(subset_fasta, genes_subset_fasta)4.3.1 Peek at genes subset FastA
head "${genes_subset_fasta}"
echo ""
grep "^>" --count "${genes_subset_fasta}">gene-Pocillopora_meandrina_HIv1___RNAseq.g29953.t1
TCACCATGGTGAATTGCCACGACTAAGTTCTCGGAAACGATCAAACCAAGTTTCCCTCCTTTCATTTGGACAGAGATCTC
GGTAGAACTTCGATCCAGCTACTTCAATGAAGCCAACAAGGCACTCGGAATCAGCTATATTGTCGAAGCCTGAAAAGTCG
AATAAATGTGATTGAATAGCTACAGATACGAAACACAAATTTGAAGTGTAACAGGAGTAACTGAAACCGATTGGATGCAT
ATGTCAGTTTAATGACGACTACTCCTTCCAAACCTGGATGGATCTAGAGAACTGGAACTTTAATATATTTTGAACTGGAA
CTTGTGCTCTCTTCCATTTACGTATGAAATGCATTGTACTTAAGTGGAGAAGATTATTCAGTTTAGACGTGTTTCGTAAT
TTGTTCAATGAAATCATAGTGGGGCATGCTTTTCCATAACAGTTTCCTTTCGCCAACAAATATTCAGGCAATGTGAAAGT
CCACTAACATCTCTATTTTAGTTCTCTAATTATGCTAGAACAACTAAATATTGTTCAATTGTTTTTTTTCGACTTCATCG
TAATTTTATCATAAGCTACAAAAAATGAGCTCCTATTCAAAACGAAAGGAAATTATAATTGAATTGAATCAGCACGGGAA
TCCTTAGGAGCTGCATCATTAACCTGTTGTAATTTTATATTCTAGCGATAGATGCGGACGTTGAAGTGGAAACGAAAGGA
180045 BLASTx
5.1 Download SwissProt
cd "${blastdbs_dir}"
curl -O https://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/complete/uniprot_sprot.fasta.gz
mv uniprot_sprot.fasta.gz 20250618-uniprot_sprot.fasta.gz
gunzip --keep 20250618-uniprot_sprot.fasta.gz % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 7 88.7M 7 6554k 0 0 6667k 0 0:00:13 --:--:-- 0:00:13 6661k 51 88.7M 51 45.9M 0 0 23.3M 0 0:00:03 0:00:01 0:00:02 23.2M 94 88.7M 94 84.0M 0 0 28.2M 0 0:00:03 0:00:02 0:00:01 28.2M100 88.7M 100 88.7M 0 0 28.9M 0 0:00:03 0:00:03 --:--:-- 28.9M5.2 Create BLASTdb
cd "${blastdbs_dir}"
"${diamond}" makedb \
--in 20250618-uniprot_sprot.fasta.gz \
--db "${diamond_db}" \
--quiet \
--threads "${threads}"5.3 Run DIAMOND BLASTx
"${diamond}" blastx \
--db "${blastdbs_dir}"/"${diamond_db}.dmnd" \
--query "${genes_subset_fasta}" \
--out "${diamond_output}" \
--outfmt 6 \
--sensitive \
--evalue 1e-10 \
--max-target-seqs 1 \
--block-size 15.0 \
--index-chunks 4 \
--threads "${threads}" \
2> "${output_dir}"/diamond-blastx.log
head "${diamond_output}"
echo ""
wc -l "${diamond_output}"gene-Pocillopora_meandrina_HIv1___RNAseq.g10233.t1 sp|Q55E58|PATS1_DICDI 27.9 290 149 8 5513 6370 1771 2004 1.90e-15 88.2
gene-Pocillopora_meandrina_HIv1___RNAseq.g10236.t1 sp|P97864|CASP7_MOUSE 36.9 130 53 4 1 387 142 243 5.64e-21 89.0
gene-Pocillopora_meandrina_HIv1___RNAseq.g10237.t1 sp|Q55E58|PATS1_DICDI 26.3 392 209 14 475 1614 1795 2118 5.44e-17 92.8
gene-Pocillopora_meandrina_HIv1___RNAseq.g10239.t1 sp|Q9W770|SPON1_CHICK 38.8 121 64 9 429 76 605 718 3.66e-12 67.0
gene-Pocillopora_meandrina_HIv1___RNAseq.g10240.t1 sp|Q55E58|PATS1_DICDI 28.4 271 134 8 1194 1994 1790 2004 4.54e-15 85.5
gene-Pocillopora_meandrina_HIv1___RNAseq.g10248.t1 sp|Q55E58|PATS1_DICDI 26.5 396 203 16 475 1614 1795 2118 1.76e-16 90.9
gene-Pocillopora_meandrina_HIv1___RNAseq.g10257.t1 sp|O89110|CASP8_MOUSE 33.8 237 123 7 3718 4386 228 444 1.21e-28 125
gene-Pocillopora_meandrina_HIv1___RNAseq.g10260.t1 sp|Q55E58|PATS1_DICDI 26.0 393 205 13 451 1584 1795 2116 3.12e-18 97.1
gene-Pocillopora_meandrina_HIv1___RNAseq.g10265.t1 sp|Q6XHB2|ROCO4_DICDI 24.7 361 174 16 448 1446 427 717 3.84e-11 71.6
gene-Pocillopora_meandrina_HIv1___RNAseq.g10267.t1 sp|O89110|CASP8_MOUSE 33.8 216 114 6 1 621 230 425 6.68e-29 122
8924 ../output/30.00-Ptua-transcriptome-GOslims/Ptuahiniensis-expressed-genes.blastx.outfmt66 GENE ONTOLOGY
6.1 Get gene IDs and SwissProt IDs
awk -F"|" '{print $1"\t"$2}' "${diamond_output}" \
| awk '{print $1"\t"$3}' \
> "${output_dir}"/gene-SPIDs.txt
head "${output_dir}"/gene-SPIDs.txt
echo ""
echo ""
wc -l "${output_dir}"/gene-SPIDs.txtgene-Pocillopora_meandrina_HIv1___RNAseq.g10233.t1 Q55E58
gene-Pocillopora_meandrina_HIv1___RNAseq.g10236.t1 P97864
gene-Pocillopora_meandrina_HIv1___RNAseq.g10237.t1 Q55E58
gene-Pocillopora_meandrina_HIv1___RNAseq.g10239.t1 Q9W770
gene-Pocillopora_meandrina_HIv1___RNAseq.g10240.t1 Q55E58
gene-Pocillopora_meandrina_HIv1___RNAseq.g10248.t1 Q55E58
gene-Pocillopora_meandrina_HIv1___RNAseq.g10257.t1 O89110
gene-Pocillopora_meandrina_HIv1___RNAseq.g10260.t1 Q55E58
gene-Pocillopora_meandrina_HIv1___RNAseq.g10265.t1 Q6XHB2
gene-Pocillopora_meandrina_HIv1___RNAseq.g10267.t1 O89110
8924 ../output/30.00-Ptua-transcriptome-GOslims/gene-SPIDs.txt6.2 Get SwissProt IDs
awk -F"|" '{print $2}' "${diamond_output}" \
| sort --unique \
> "${output_dir}"/SPIDs.txt
head "${output_dir}"/SPIDs.txt
echo ""
echo ""
wc -l "${output_dir}"/SPIDs.txtA0A0C2SRU0
A0A0D3QS97
A0A0G2JXT6
A0A0G2JZ79
A0A0G2K2P5
A0A0G2KIZ8
A0A0R0H9T5
A0A0R3K2G2
A0A0R4I9Y1
A0A0R4IB93
6541 ../output/30.00-Ptua-transcriptome-GOslims/SPIDs.txt6.3 Retrieve UniProt records
A difference in number of records could be due to retrieval from only “reviewed” records, while BLAST may have included both “reviewed” and “unreviewed.” SwissProt records
python3 \
../../M-multi-species/code/uniprot-retrieval.py \
"${output_dir}"/SPIDs.txt \
"${output_dir}"/
gunzip "${output_dir}"/uniprot-retrieval.tsv.gz
echo ""
echo ""
wc -l "${output_dir}"/uniprot-retrieval.tsv500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
500 / 500
41 / 41
6554 ../output/30.00-Ptua-transcriptome-GOslims/uniprot-retrieval.tsv6.4 Map GO to Genes
# Read gene-SPIDs.txt
gene_spids <- read.delim(file.path(output_dir, "gene-SPIDs.txt"), header = FALSE, stringsAsFactors = FALSE)
colnames(gene_spids) <- c("GeneID", "Entry")
# Read uniprot-retrieval.tsv
uniprot <- read.delim(
file.path(output_dir, "uniprot-retrieval.tsv"),
header = TRUE,
stringsAsFactors = FALSE,
check.names = FALSE
)
# Merge on Entry
gene_SPID_GOID_merged <- merge(gene_spids, uniprot[, c("Entry", "Gene Ontology IDs")], by = "Entry", all.x = TRUE)
# View result
str(gene_SPID_GOID_merged)'data.frame': 8924 obs. of 3 variables:
$ Entry : chr "A0A0C2SRU0" "A0A0D3QS97" "A0A0D3QS97" "A0A0G2JXT6" ...
$ GeneID : chr "gene-Pocillopora_meandrina_HIv1___RNAseq.g1925.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g25235.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g25230.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g18909.t1" ...
$ Gene Ontology IDs: chr "GO:0004609; GO:0005739; GO:0006646" "GO:0005576; GO:0016055; GO:0090090; GO:1990699" "GO:0005576; GO:0016055; GO:0090090; GO:1990699" "GO:0004438; GO:0005635; GO:0005737; GO:0005783; GO:0005793; GO:0006897; GO:0032587; GO:0046856; GO:0048471; GO:"| __truncated__ ...6.4.1 Write merged to file
# Optionally, write to file
write.table(gene_SPID_GOID_merged,
file = file.path(output_dir, "gene-SPIDs-GOIDs.tsv"),
sep = "\t",
row.names = FALSE,
quote = FALSE)6.5 Clean up merged
full.gene.df <- as.data.frame(gene_SPID_GOID_merged)
# Clean whitespace, filter NA/empty rows, select columns, and split GO terms using column name variables
gene.GO.df <- full.gene.df %>%
mutate(!!"Gene Ontology IDs" := str_replace_all(.data[["Gene Ontology IDs"]], "\\s*;\\s*", ";")) %>% # Clean up spaces around ";"
filter(!is.na(.data[["GeneID"]]) & !is.na(.data[["Gene Ontology IDs"]]) & .data[["Gene Ontology IDs"]] != "") %>%
dplyr::select(all_of(c("GeneID", "Gene Ontology IDs")))
str(gene.GO.df)'data.frame': 8783 obs. of 2 variables:
$ GeneID : chr "gene-Pocillopora_meandrina_HIv1___RNAseq.g1925.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g25235.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g25230.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g18909.t1" ...
$ Gene Ontology IDs: chr "GO:0004609;GO:0005739;GO:0006646" "GO:0005576;GO:0016055;GO:0090090;GO:1990699" "GO:0005576;GO:0016055;GO:0090090;GO:1990699" "GO:0004438;GO:0005635;GO:0005737;GO:0005783;GO:0005793;GO:0006897;GO:0032587;GO:0046856;GO:0048471;GO:0052629;GO:0106018" ...6.6 Flatten gene GOID file
flat.gene.GO.df <- gene.GO.df %>% separate_rows(!!sym("Gene Ontology IDs"), sep = ";")
str(flat.gene.GO.df)tibble [104,557 × 2] (S3: tbl_df/tbl/data.frame)
$ GeneID : chr [1:104557] "gene-Pocillopora_meandrina_HIv1___RNAseq.g1925.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g1925.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g1925.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g25235.t1" ...
$ Gene Ontology IDs: chr [1:104557] "GO:0004609" "GO:0005739" "GO:0006646" "GO:0005576" ...6.7 Group by GOID
grouped.gene.GO.df <- flat.gene.GO.df %>%
group_by(!!sym("Gene Ontology IDs")) %>%
summarise(!!"GeneID" := paste(.data[["GeneID"]], collapse = ","))
str(grouped.gene.GO.df)tibble [12,365 × 2] (S3: tbl_df/tbl/data.frame)
$ Gene Ontology IDs: chr [1:12365] "GO:0000001" "GO:0000002" "GO:0000009" "GO:0000012" ...
$ GeneID : chr [1:12365] "gene-Pocillopora_meandrina_HIv1___RNAseq.15379_t" "gene-Pocillopora_meandrina_HIv1___RNAseq.g13404.t2,gene-Pocillopora_meandrina_HIv1___TS.g6603.t1,gene-Pocillopo"| __truncated__ "gene-Pocillopora_meandrina_HIv1___RNAseq.g1398.t1" "gene-Pocillopora_meandrina_HIv1___RNAseq.g2292.t1,gene-Pocillopora_meandrina_HIv1___RNAseq.g12407.t1,gene-Pocil"| __truncated__ ...6.8 Vectorize GOIDs
# Vector of GO IDs
go_ids <- grouped.gene.GO.df[["Gene Ontology IDs"]]
str(go_ids) chr [1:12365] "GO:0000001" "GO:0000002" "GO:0000009" "GO:0000012" ...6.9 Prepare GOslim OBO
# Find GSEAbase installation location
gseabase_location <- find.package("GSEABase")
# Load path to GOslim OBO file
goslim_obo_destintation <- file.path(gseabase_location, "extdata", goslims_obo, fsep = "/")
# Download the GOslim OBO file
download.file(url = goslims_url, destfile = goslim_obo_destintation)
# Loads package files
gseabase_files <- system.file("extdata", goslims_obo, package="GSEABase")6.10 GOslims from OBO
# Create GSEAbase GOCollection using `go_ids`
myCollection <- GOCollection(go_ids)
# Retrieve GOslims from GO OBO file set
slim <- getOBOCollection(gseabase_files)
str(slim)Formal class 'OBOCollection' [package "GSEABase"] with 7 slots
..@ .stanza :'data.frame': 153 obs. of 1 variable:
.. ..$ value: chr [1:153] "Root" "Term" "Term" "Term" ...
..@ .subset :'data.frame': 22 obs. of 1 variable:
.. ..$ value: chr [1:22] "Rhea list of ChEBI terms representing the major species at pH 7.3." "Term not to be used for direct annotation" "Terms planned for obsoletion" "AGR slim" ...
..@ .kv :'data.frame': 2110 obs. of 3 variables:
.. ..$ stanza_id: chr [1:2110] ".__Root__" ".__Root__" ".__Root__" ".__Root__" ...
.. ..$ key : chr [1:2110] "format-version" "data-version" "synonymtypedef" "synonymtypedef" ...
.. ..$ value : chr [1:2110] "1.2" "go/releases/2025-06-01/subsets/goslim_generic.owl" "syngo_official_label \"label approved by the SynGO project\"" "systematic_synonym \"Systematic synonym\" EXACT" ...
..@ evidenceCode: chr [1:26] "EXP" "IDA" "IPI" "IMP" ...
..@ ontology : chr NA
..@ ids : chr [1:141] "GO:0000228" "GO:0000278" "GO:0000910" "GO:0001618" ...
..@ type : chr "OBO"6.11 Biological Process GOslims
# Retrieve Biological Process (BP) GOslims
slimdf <- goSlim(myCollection, slim, "BP", verbose)
str(slimdf)'data.frame': 72 obs. of 3 variables:
$ Count : int 93 23 21 447 56 89 23 4 82 55 ...
$ Percent: num 1.143 0.283 0.258 5.495 0.688 ...
$ Term : chr "mitotic cell cycle" "cytokinesis" "cytoplasmic translation" "immune system process" ...6.12 Map GO to GOslims
# List of GOslims and all GO IDs from `go_ids`
gomap <- as.list(GOBPOFFSPRING[rownames(slimdf)])
# Maps `go_ids` to matching GOslims
mapped <- lapply(gomap, intersect, ids(myCollection))
# Append all mapped GO IDs to `slimdf`
# `sapply` needed to apply paste() to create semi-colon delimited values
slimdf$GO.IDs <- sapply(lapply(gomap, intersect, ids(myCollection)), paste, collapse=";")
# Remove "character(0) string from "GO.IDs" column
slimdf$GO.IDs[slimdf$GO.IDs == "character(0)"] <- ""
# Add self-matching GOIDs to "GO.IDs" column, if not present
for (go_id in go_ids) {
# Check if the go_id is present in the row names
if (go_id %in% rownames(slimdf)) {
# Check if the go_id is not present in the GO.IDs column
# Also removes white space "trimws()" and converts all to upper case to handle
# any weird, "invisible" formatting issues.
if (!go_id %in% trimws(toupper(strsplit(slimdf[go_id, "GO.IDs"], ";")[[1]]))) {
# Append the go_id to the GO.IDs column with a semi-colon separator
if (length(slimdf$GO.IDs) > 0 && nchar(slimdf$GO.IDs[nrow(slimdf)]) > 0) {
slimdf[go_id, "GO.IDs"] <- paste0(slimdf[go_id, "GO.IDs"], "; ", go_id)
} else {
slimdf[go_id, "GO.IDs"] <- go_id
}
}
}
}
str(slimdf)'data.frame': 72 obs. of 4 variables:
$ Count : int 93 23 21 447 56 89 23 4 82 55 ...
$ Percent: num 1.143 0.283 0.258 5.495 0.688 ...
$ Term : chr "mitotic cell cycle" "cytokinesis" "cytoplasmic translation" "immune system process" ...
$ GO.IDs : chr "GO:0000022;GO:0000070;GO:0000082;GO:0000086;GO:0000132;GO:0000281;GO:0000282;GO:0007052;GO:0007064;GO:0007076;G"| __truncated__ "GO:0000281;GO:0000282;GO:0000911;GO:0000915;GO:0007110;GO:0007111;GO:0007112;GO:0032465;GO:0032466;GO:0032467;G"| __truncated__ "GO:0001731;GO:0001732;GO:0002182;GO:0002183;GO:0002184;GO:0002188;GO:0002191;GO:0017183;GO:0140708;GO:1900248;G"| __truncated__ "GO:0001771;GO:0001774;GO:0001776;GO:0001777;GO:0001779;GO:0001780;GO:0001782;GO:0001867;GO:0001913;GO:0001916;G"| __truncated__ ...6.13 Flatten GOslims
# "Flatten" file so each row is single GO ID with corresponding GOslim
# rownames_to_column needed to retain row name info
slimdf_separated <- as.data.frame(slimdf %>%
rownames_to_column('GOslim') %>%
separate_rows(GO.IDs, sep = ";"))
# Group by unique GO ID
grouped_slimdf <- slimdf_separated %>%
filter(!is.na(GO.IDs) & GO.IDs != "") %>%
group_by(GO.IDs) %>%
summarize(GOslim = paste(GOslim, collapse = ";"),
Term = paste(Term, collapse = ";"))
str(grouped_slimdf)tibble [5,598 × 3] (S3: tbl_df/tbl/data.frame)
$ GO.IDs: chr [1:5598] " GO:0000278" " GO:0002181" " GO:0002376" " GO:0003014" ...
$ GOslim: chr [1:5598] "GO:0000278" "GO:0002181" "GO:0002376" "GO:0003014" ...
$ Term : chr [1:5598] "mitotic cell cycle" "cytoplasmic translation" "immune system process" "renal system process" ...6.14 Counts of GOslims
slimdf.sorted <- slimdf %>% arrange(desc(Count))
slim.count.df <- slimdf.sorted %>%
dplyr::select(Term, Count, Percent)
str(slim.count.df)'data.frame': 72 obs. of 3 variables:
$ Term : chr "anatomical structure development" "cell differentiation" "signaling" "immune system process" ...
$ Count : int 1736 742 728 447 282 263 246 202 200 184 ...
$ Percent: num 21.34 9.12 8.95 5.49 3.47 ...6.14.1 Write GOslims to file
Need to create a column name for GOslimIDs from data frame rownames.
# Create header vector
header <- c("GOslimID", colnames(slim.count.df))
# Write header to file
writeLines(paste(header, collapse = "\t"),
file.path(output_dir, "GOslim-counts.tsv"))
# Append data frame contents to existing file, which contains header info
write.table(
slim.count.df,
file = file.path(output_dir, "GOslim-counts.tsv"),
sep = "\t",
row.names = TRUE,
quote = FALSE,
col.names = FALSE,
append = TRUE
)RESULTS
Multispecies barplots were created of the top 10 GOslims with the highest GO term counts.
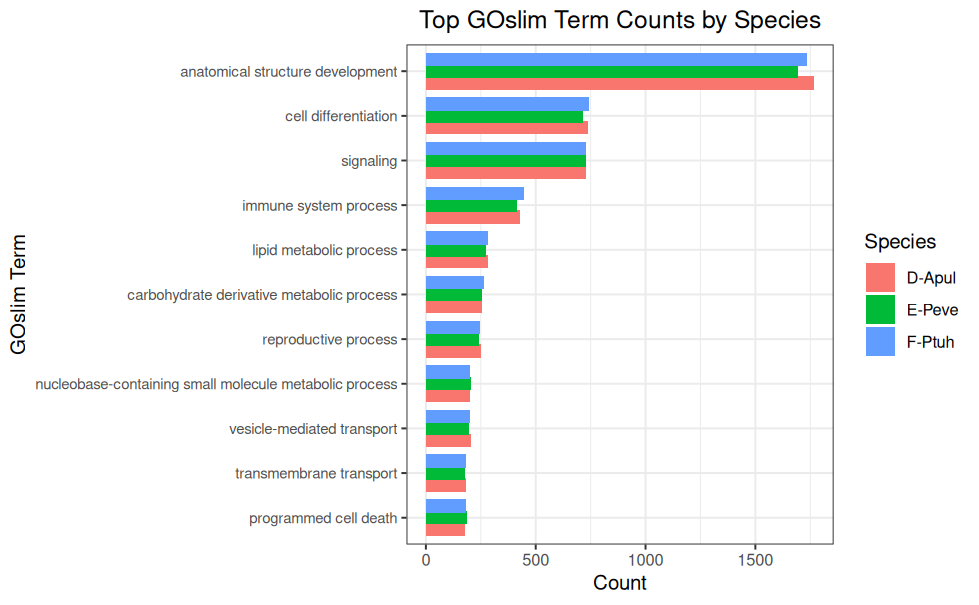
Plots were generated with the following code:
# Define file paths and species names
files <- list(
"D-Apul" = "~/gitrepos/urol-e5/deep-dive-expression/D-Apul/output/30.00-Apul-transcriptome-GOslims/GOslim-counts.tsv",
"E-Peve" = "~/gitrepos/urol-e5/deep-dive-expression/E-Peve/output/30.00-Peve-transcriptome-GOslims/GOslim-counts.tsv",
"F-Ptuh" = "~/gitrepos/urol-e5/deep-dive-expression/F-Ptuh/output/30.00-Ptua-transcriptome-GOslims/GOslim-counts.tsv"
)
# Read and combine data
goslim_data <- map2_dfr(
files,
names(files),
~ read_tsv(.x, show_col_types = FALSE) %>%
mutate(Species = .y)
)
# Find the top 10 Terms by Count for each species
top_terms <- goslim_data %>%
group_by(Species) %>%
slice_max(order_by = Count, n = 10, with_ties = FALSE) %>%
ungroup() %>%
distinct(Term)
# Filter the data to only include these Terms
goslim_top <- goslim_data %>%
filter(Term %in% top_terms$Term)
# Plot: Term on Y, Count on X
ggplot(goslim_top, aes(y = fct_reorder(Term, Count), x = Count, fill = Species)) +
geom_bar(stat = "identity", position = position_dodge(width = 0.8)) +
labs(
title = "Top GOslim Term Counts by Species",
y = "GOslim Term",
x = "Count"
) +
theme_bw() +
theme(
axis.text.y = element_text(size = 8),
plot.title = element_text(hjust = 0.5)
)